
- MS-COMET-QE-22
- REUSE
- Матрица ошибок
- Сравнение метрик
- Метрики качества линейных регрессионных моделей
- Отбор переменных в моделях линейной регрессии
- Репрезентативность выборочных данных
- AUC-PR
- Оценка качества классификатора: Точность и Полнота
- Комбинирование точности и полноты
- Кривая точность-полнота
- Преимущества кривой точность-полнота
- Примеры кривых точность-полнота
- Подходы к человеческой оценке качества перевода
- Customer Satisfaction Score
- Net Promoter Score
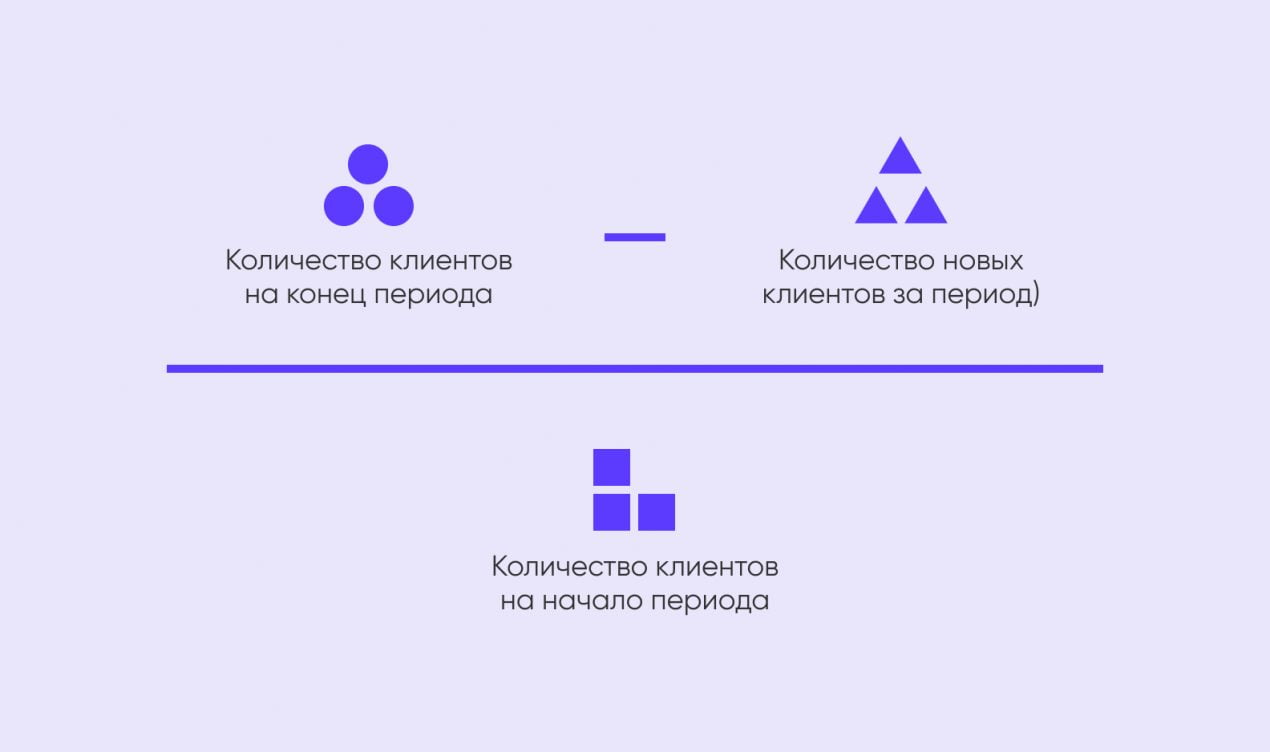
- Retention Rate
- Conversion Rate
- Adoption Rate
- MATESE-QE
- Менеджерские метрики
- Burn Rate
- Flow Efficiency
- Team Velocity
- Среднее количество багов за спринт
- Полнота
- Часто задаваемые вопросы о метриках эффективности
- Для чего оценивать эффективность сайта по метрикам?
- Какие инструменты оценки эффективности можно использовать?
- Как распорядиться полученными данными?
- AUC-ROC
- Безреференсные системы оценки
- Специфичность
- Точность (Accuracy)
- Меткость
- Ключевых метрик для оценки эффективности опроса
- Технические метрики
- Test Coverage
- Скорость загрузки страниц
- ER-диаграмма
- Использование зрелого фреймворка
- Проверка дублирования кода
- Функция потерь логистической регрессии (Logistic loss function, Log Loss).
- Коэффициент корреляции Пирсона
- Метрики эффективности социальных сетей
- Количество подписчиков
- CPF – стоимость подписчика
- ER – уровень вовлеченности
- Логика развития метрик
- Какие метрики качества используются для оценки алгоритмов машинного обучения
- F1-мера
MS-COMET-QE-22
Модель MS-COMET-QE-22 (Kocmi et al., 2022) основана на архитектуре COMET без использования референса. Однако она была обучена на более крупном наборе данных, содержащем оценки качества перевода на 113 языках. Создатели модели также уделили особое внимание предобработке оценок, исключая из набора данные с потенциально низким качеством.
REUSE
Метрика REUSE (REference-free UnSupervised quality Estimation Metric, Mukherjee and Shrivastava, 2022) основана на оценке качества перевода как на уровне предложений, так и на уровне словосочетаний. Для расчета этой метрики переведенные и исходные предложения дополнительно разбиваются на словосочетания. Близость словосочетаний оценивается на основе контекстных эмбеддингов из модели BERT, а близость предложений – на основе эмбеддингов модели LaBSE (Language-agnostic BERT Sentence Embeddings, Feng et al., 2020). Итоговое значение метрики REUSE получается путем усреднения оценок степени близости по всем словосочетаниям и предложениям.
Матрица ошибок
Приведем пример с использованием аналитической платформы в страховой компании для принятия решений о целесообразности страхования объектов. Важно правильно классифицировать объекты для определения страхования. Возможны две ошибки:
- Ложная тревога: объект неправильно классифицирован как целесообразный для страхования, что влечет потенциальную потерю страховой премии.
- Пропуск цели: объект неправильно классифицирован как невыгодный для страхования, что может привести к значительным потерям из-за страхового случая.
Важнее предотвратить пропуск цели, чем ложную тревогу. Матрица ошибок классификации, также известная как таблица сопряженности, выглядит следующим образом:
| Положительный класс | Отрицательный класс | |
|---|---|---|
| Истинно положительный (TP) | Верно классифицированные положительные примеры | Ложноположительный (FP) |
| Ложноотрицательный (FN) | Ложноотрицательный (FN) | Верно классифицированные отрицательные примеры (TN) |
Сравнение метрик
Подведем итоги, кратко резюмируя преимущества и недостатки рассмотренных мер качества классификационных моделей.
| Метрика | Преимущества | Недостатки |
|---|---|---|
| Меткость | Хорошо интерпретируется | Чувствительна к дисбалансу классов. Неадекватно отражает точность классификации. |
| Точность | Не чувствительна к дисбалансу классов. | Отражает качество классификации только для положительного класса. |
| Полнота | Не чувствительна к дисбалансу классов. | Не учитывает отрицательные классификации. |
| Специфичность | Просто вычисляется и интерпретируется. | Характеризует способность модели распознавать только один класс. |
| F1-мера | Позволяет найти баланс между точностью и полнотой. | Чувствительность к дисбалансу, отсутствие симметрии. |
| P4 | Симметрична относительно инверсии классов. | Чувствительность к дисбалансу классов. |
| AUC-ROC | Наглядна, хорошо интерпретируется. | В условиях дисбаланса классов завышает качество модели. Не отражает изменения баланса классов. |
| AUC-PR | Наглядна, хорошо интерпретируется. | Не учитывает отрицательные классификации. |
| Коэффициент Мэтьюса | Более информативен, поскольку использует все типы результатов классификации. | Не может применяться, если один из множителей в знаменателе обращается в 0. |
| LogLoss | Устойчивость к выбросам в данных, простота вычисления. | Сложность интерпретации из-за нелинейного характера. |
Метрики качества линейных регрессионных моделей
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
AUC-PR
AUC-PR-кривые определяются аналогично AUC-ROC-кривым, но только по оси абсцисс у них откладываются значения полноты, а по оси ординат — точности.
Точность и полнота — две наиболее важные метрики, на которые следует обращать внимание при оценке качества модели бинарной классификации в условиях несбалансированности классов. Они помогают увидеть, какая часть фактически положительных наблюдений была классифицирована правильно, и какие среди классифицированных как положительные, были истинноположительными.
Если точность равна 1, то ложноположительные классификации отсутствуют. Но это ничего не говорит о том, были ли распознаны все положительные примеры. Если полнота равна 1, то все положительные объекты были распознаны правильно, а ложноотрицательные классификации отсутствуют. При этом ничего не говорится о том, сколько было допущено ложноположительных классификаций.
Оценка качества классификатора: Точность и Полнота
Таким образом, точность и полнота не особенно полезны для оценки качества классификатора, если их использовать по отдельности. В задаче классификации оценка точности, равная 1 для класса , означает, что каждый элемент, помеченный как принадлежащий классу , действительно принадлежит к классу , но ничего не говорит о количестве элементов из класса , которые не были правильно классифицированы. Тогда как полнота, равная 1, означает, что каждый элемент из класса был помечен как принадлежащий к классу , но ничего не говорит о том, сколько элементов из других классов были также неправильно классифицированы как принадлежащие к классу .
Обычно показатели точности и полноты не используются по отдельности. Вместо этого либо значения одной меры сравниваются с фиксированным уровнем другой (например, точность на уровне полноты 0.75), либо обе меры объединяются в один показатель. Примерами такой комбинации и является -мера — взвешенное гармоническое среднее точности и полноты.
Комбинирование точности и полноты
Еще одним способом комбинирования точности и полноты в задаче оценки качества классификации являются так называемые кривые полнота-точность, которые строятся в системе координат, где по оси абсцисс откладывается полнота, а по оси ординат — точность. Кривая точность-полнота показывает, как выбор порога влияет на точность классификатора, а также помогает выбрать лучшее значение дискриминационного порога для определенного баланса классов.
Кривая точность-полнота
| Точка 1 | Дискриминационный порог = 1 |
| Точка 2 | Идеальный классификатор (1,1) |
| Точка 3 | Дискриминационный порог = 0 |
| Точка 4 | Оптимальное значение порога |
Преимущества кривой точность-полнота
Аналогично -кривой, площадь под -кривой (для отличия от ее часто называют ) отражает качество классификатора и позволяет сравнивать кривые, соответствующие различным балансам классов и значениям порога. Чем выше площадь, тем лучше работает модель.
Пунктирная линия внизу графика соответствует бесполезному классификатору (no-skill model — модель без навыков, или базовая модель), уровень которой изменяется при изменении баланса классов. Такая модель будет присваивать рейтинг 0.5 для любого примера.
Примеры кривых точность-полнота
- Рисунок 7. Кривая точность-полнота при фиксированном балансе классов
- Рисунок 8. Кривая точность-полнота для идеальной модели
- Рисунок 9. Кривая точность-полнота для модели хуже бесполезной
Очевидный способ повысить качество плохой модели без каких-либо настроек — просто инвертировать классы (класс 0 изменить на класс 1). Это автоматически приведет к повышению точности по сравнению с базовой моделью.
Обычно плохая -кривая классификатора указывает на то, что в обучающих данных присутствуют проблемы: они содержат шум или классы в них плохо выражены (модель не может выявить закономерность, в соответствии с которой один класс отличается от другого). В этом случае не превышает доли положительных примеров обучающей выборке.
Возможен гибридный случай, когда плохая модель работает лучше, чем модель без навыков, но для определенных пороговых значений.
Подходы к человеческой оценке качества перевода
В конечном счете любое приложение компании по разработке программного обеспечения создают для пользователей. Их удобство и удовлетворение — важнейшие показатели для бизнеса, которые будут конвертироваться в прибыль.
Customer Satisfaction Score
CSAT позволяет оценить качество конкретного взаимодействия пользователя с сервисом. В таком случае респонденту задают короткий прицельный вопрос. Например, просят оценить удобство навигации, отслеживание доставки или понятность программы лояльности — выбирая из вариантов хорошо, плохо и нейтрально.
Результат опроса может не отражать лояльность пользователя в широком смысле: возможно, конкретная услуга ему понравилась, а все остальное — нет. Но CSAT позволяет быстро оценивать отдельные составляющие сервиса, с которыми взаимодействовали пользователи.
Это может быть важно для:
Net Promoter Score
Метрика NPS рассчитывается по ответу на вопрос насколько вы порекомендуете сервис друзьям и знакомым?. Обычно предлагается оценить вероятность по десятибалльной шкале.
В отличие от CSAT, по которой видна удовлетворенность конкретным взаимодействием в данный момент времени, NPS показывает общую лояльность к приложению в целом, за весь период его использование.
NPS дает понять, как много пользователей:
Retention Rate
Приложения создаются для того, чтобы ими пользовались регулярно, поэтому показатель возвращаемости важен для бизнеса. В зависимости от назначения продукта, эту метрику можно отслеживать за день, за неделю или за месяц.
Показатель возвращаемости нужен, чтобы:
Conversion Rate
Метрика разработки программного обеспечения показывает, сколько людей среди посетителей приложения совершили целевое действие. Это может быть подписка, покупка, клик по нужной кнопке — в качестве целевого действия можно выбирать то, что нужно в рамках конкретного анализа. Коэффициент конверсии рассчитывается в процентах. Скажем, всего на странице за день было 200 человек, из них 20 кликнули на нужную кнопку — выходит конверсия 10%.
У этой метрики одно назначение — понять, насколько привлекателен CTA-элемент для аудитории.
Если конверсия низкая, можно думать о ее причинах. Это могут быть:
Adoption Rate
Эта метрика показывает, насколько полно люди пользуются продуктом: задействуют ли они все возможности приложения или выполняют в нем очень ограниченные операции. Показатель можно рассчитать, разделив число новых пользователей конкретного раздела приложения на число всех пользователей.
По метрике видно:
MATESE-QE
Модель MATESE-QE (Perrella et al., 2022) имеет в своей основе мультиязычную модель-энкодер с архитектурой трансформера, дообученную, чтобы выявлять ошибки перевода.
Найденные в каждом предложении ошибки модель классифицирует по степени серьезности: в диапазоне от несущественных (им присваивается оценка -1) до максимально существенных (оценка -5). Итоговая оценка качества перевода всего текста формируется в логике, позаимствованной у Freitag et al. (2021a) – путем усреднения оценок для отдельных предложений, составляющих текст.
Дообучение выполнено на данных MQM. Сравнив результаты несколько базовых моделей (XLM-RoBERTa, RoBERTa, mBART), создатели метрики остановились на XLM-RLARGE.
Менеджерские метрики
Успех всего проекта зависит от эффективности процесса разработки. Бюджет, сроки, приоритетные задачи — все это следует выбирать и корректировать на основе конкретных цифр. Менеджерские метрики помогают омпаниям по разработке программного обеспечения оценить работу команды.
Burn Rate
Это одна из самых главных менеджерских метрик разработки программного обеспечения: диаграмма сгорания задач показывает, сколько работы уже выполнено и сколько осталось. Метрику можно посмотреть за:
График представляет собой кривые, идущие вниз: они показывают динамику решения задач. По шкале X отмечают количество дней до окончания спринта или до релиза. По шкале Y — число задач. Одна из линий графика демонстрирует то, как быстро планировалось выполнить работу. Вторая линия — то, как работа идет на самом деле. Диаграмма может выглядеть, например, так:
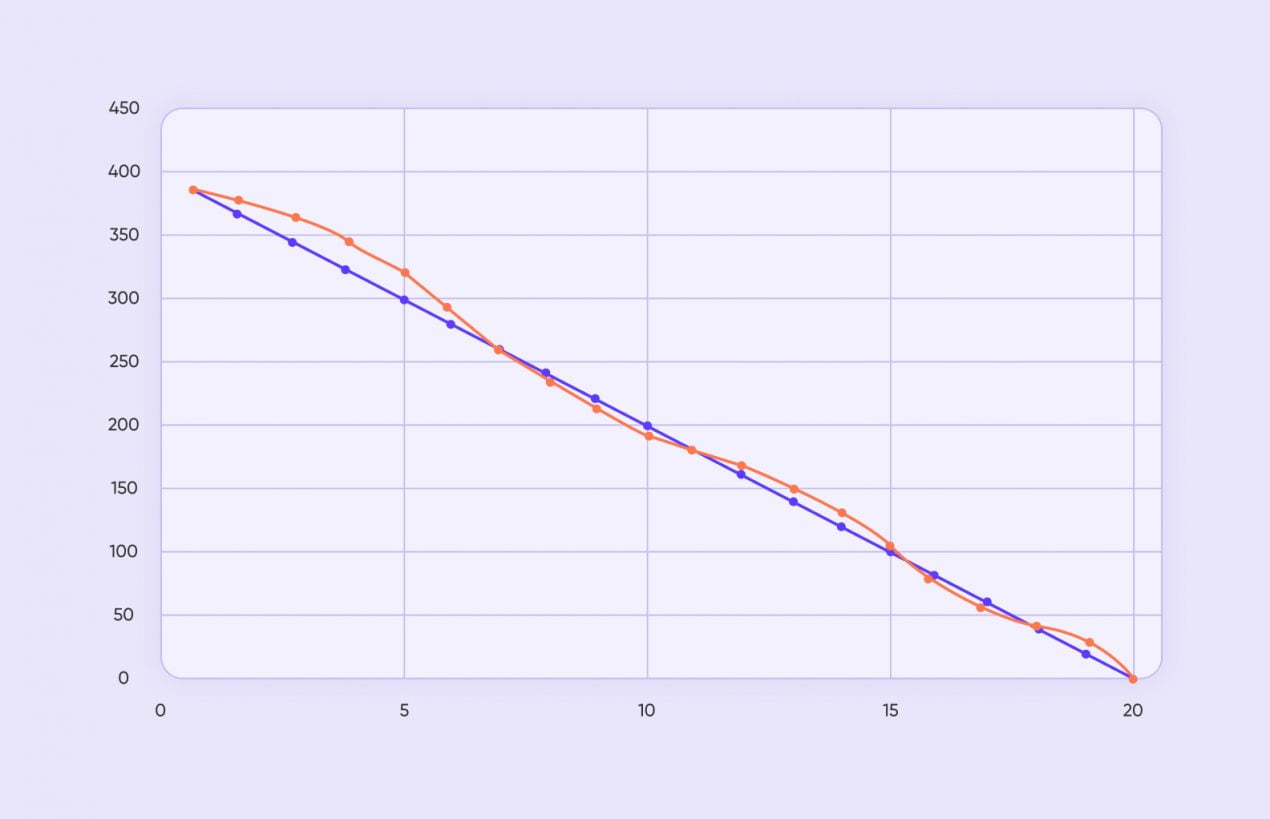
Если диагональ, отражающая реальную работу, будет иметь более крутой наклон, значит, работа выполняется быстрее, чем планировалось. Если она будет более пологой — дело идет медленнее. Также график реальной работы может быть сильно искривленным. Например, сначала идти по горизонтали (когда никакие задачи не решаются), а потом резко пойти вниз (если команда, оказывающая услуги по разработке программного обеспечения, работает в ударном темпе).
По диаграмме сгорания задач смотрят:
Хотите разобраться, чем полезна диаграмма сгорания задач на примере реального проекта? Читайте наш кейс:
Flow Efficiency
разработке программного обеспечения на заказ есть стадии активной работы и время ожидания: когда для того, чтобы приступить к задаче, не хватает информации или ресурсов. Минимизировать простои — одна из задач менеджера. Соотношение времени работы ко всему времени с учетом простоя и называют эффективностью потока.

Например, если над задачей работали 3 дня, а еще 2 она «висела» в ожидании, когда разработчик для нее освободится, формула эффективности потока будет: 3/(2+3) *100%.
Эта метрика разработки программного обеспечения служит, чтобы:
Team Velocity
метрика разработки программного обеспечения демонстрирует, какой объем работы команда способна выполнить за спринт. Для вычисления показателя производительности в продуктовых командах используют стори поинты (story points) — с их помощью каждой задаче в бэклоге назначают вес в зависимости от ее сложности. Если вы работаете со студией, вместо стори поинтов оценка идет в часах: так всем проще и понятнее.
Сумма всех стори поинтов или всех часов за спринт — это и есть производительность.
Метрику используют, чтобы:
Среднее количество багов за спринт
Баги при разработке ПО возникают неизбежно. Чтобы их контролировать, можно подсчитывать количество в каждом спринте. На примере нескольких спринтов можно выявить нормальный показатель для конкретного проекта и в дальнейшем равняться на него. А существенные отклонения от средней цифры — повод задуматься.
Вот что можно увидеть по количеству багов за спринт:
Полнота
Полнота, известная еще как чувствительность или доля истинноположительных примеров (TPR — true positive rate), определяется как число истинноположительных классификаций относительно общего числа положительных наблюдений:
Таким образом, полноту можно рассматривать как способность классификатора обнаруживать определенный класс. Графически полноту можно проиллюстрировать с помощью рисунка:
Рисунок 3. Полнота
Точность и полноту для каждого класса легко определять с помощью матрицы ошибок. Точность равна отношению соответствующего диагонального элемента матрицы и суммы элементов всей строки класса, а полнота — отношению диагонального элемента матрицы и суммы элементов всего столбца класса.
где — класс, — число элементов столбца (равно числу классов), — номер элемента в столбце, — элемент матрицы ошибок.
Часто задаваемые вопросы о метриках эффективности
Изучение совокупности показателей поможет понять:
Для чего оценивать эффективность сайта по метрикам?
Поскольку главная задача веб-ресурса – привлекать целевую аудиторию и конвертировать ее в клиентуру, необходимо отслеживать результативность всех показателей, влияющих на достижение цели.
Анализ метрик сайта позволяет определить каналы, через которые приходит качественный трафик, выявить контент, наиболее привлекательный для пользователей, и сделать акцент на наиболее действенных методах продвижения товаров и услуг.
Какие инструменты оценки эффективности можно использовать?
В цифровом маркетинге существует множество удобных сервисов для сбора данных и определения ключевых метрик. Перечислим самые популярные:
Как распорядиться полученными данными?
По итогам проведенного анализа можно понять, успешна ли ваша маркетинговая стратегия в целом, приходит ли на сайт целевая аудитория, готовая к приобретению продукта.
Чтобы обнаружить проблемы на сайте, воспользуйтесь одним из двух способов:
Например, вы провели SEO-оптимизацию статьи на сайте и вскоре отметили прирост органического трафика. Поисковики стали предлагать ваши материалы пользователям с релевантными запросами.
Метрики для оценки эффективности – это те сигнальные огоньки, по которым вы поймете, как реально обстоят дела с продвижением товаров или услуг. Те инструменты и приемы, которые казались многообещающими, на практике могут не сработать. И напротив, очень хорошо проявят себя методы, на которые вы не планировали делать ставку. Опирайтесь не на интуицию, а на точные маркетинговые данные, и ваши шансы на успех вырастут многократно.
AUC-ROC
-кривая, или кривая рабочих характеристик приемника (Receiver Operating Characteristics curve), позволяет не только оценить качество работы классификатора, но и исследовать его поведение при различных значениях дискриминационного порога. Технология оценки качества моделей бинарной классификации с помощью -кривых известна как ROC-анализ.
Рассмотрим совместно и классификатора. показывает, насколько хорошо модель классифицирует положительные примеры. Очевидно, что если все положительные примеры классифицированы правильно (т.е. число ложноотрицательных случаев равно 0), то . показывает, насколько хорошо модель классифицирует отрицательные примеры. Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то .
Таким образом, по отдельности и характеризуют способность модели распознавать только один из классов. Но их совместное использование помогает создать метрику, которая позволяет выбирать значение дискриминационного порога, который оптимально балансирует модель между способностью распознавать положительные и отрицательные примеры. Именно эта задача и решается с помощью -кривой.
Действительно, если изменять дискриминационный порог от 0 до 1 и наносить по оси абсцисс точки , а по оси ординат , то полученный график и будет -кривой. Величину называют долей ложноположительных классификаций (false positive rate) или показателем ложной тревоги. Она вычисляется следующим образом:
При пороге, равном 1, все примеры будут классифицированы как отрицательные (, ), а при пороге, равном 0, — как положительные (, ). Поэтому -кривая всегда идет от точки (0,0) до точки (1,1).
Рисунок 5. ROC-кривая
Несложно увидеть, что для идеальной модели -кривая превращается в ломаную, проходящую через точки (0,0), (0,1) и (1,1). При этом площадь под -кривой ( — Area Under Curve) окажется равной 1. Площадь под кривой выделена на рисунке светло-серым цветом.
Точка (0,1) соответствует идеальному состоянию модели, в котором и , и одновременно равны 1. Т.е. модель одинаково хорошо «научилась» работать как с положительными, так и с отрицательными примерами при существующем в обучающей выборке балансе классов.
Идеальная модель является скорее гипотетической и на практике, как правило, недостижима. Поэтому обычно приходится иметь дело с -кривыми, которые не проходят через точку (0,1), а приближаются к ней на определенное расстояние. Соответственно и оказывается меньше 1.
Таким образом показатель является удобной мерой качества классификатора относительно идеального. Принята следующая шкала оценки качества.
0.9 – 1Отличное
0.8 – 0.9Очень хорошее
0.7 – 0.8Хорошее
0.6 – 0.7Удовлетворительное
0.5 – 0.7Плохое
Если , то -кривая превращается в линию, проходящую через точки (0,0) и (1,1), которая соответствует бесполезному классификатору, работающему как случайный предсказатель. Если , то получается модель, которая работает хуже случайного предсказателя и от ее использования следует отказаться.
Безреференсные системы оценки
В NLP cуществует отдельная задача Quality Estimation (QE) – предсказание качества машинного перевода в отсутствие референса, то есть без ориентира в виде эталонного перевода, выполненного человеком. Задача QE может решаться как на уровне отдельных слов, так и на уровне предложений.
Современный подход к QE заключается в дообучении мощных предобученных многоязычных нейросетевых моделей-энкодеров (таких как BERT, XLM-R) для прямого сравнения машинного перевода и первоисточника на исходном языке.
В последние годы модели QE достигли довольно высокого уровня корреляции с человеческой оценкой качества перевода предложений (коэффициент корреляции Пирсена до 0.9 для некоторых языковых пар – WMT2020: Specia et al., 2020).
Оценки, получаемые на выходе моделей QE, по сути представляют собой безреференсные метрики качества машинного перевода. Их можно рассматривать как альтернативу значительно более распространенным традиционным и референсным нейросетевым метрикам.
Обучение моделей QE выполняется на датасетах, содержащих человеческие оценки качества перевода. Также выполненные человеком оценки используются и при определении степени адекватности метрик качества машинного перевода. Рассмотрим подробней, как получают такие данные.
Специфичность
Специфичность классификатора — это доля истинноотрицательных (True Negative Rate — TNR) классификаций в общем числе отрицательных классификаций:
показывает, насколько хорошо модель классифицирует отрицательные примеры. Поясним это с помощью рисунка.
Рисунок 4. Специфичность
Точность (Accuracy)
Точность — это доля правильно классифицированных объектов среди всех объектов. Эта метрика является одной из самых простых и интуитивно понятных, однако она может быть не всегда полезна, особенно в случае несбалансированных классов.
Пример: Предположим, у нас есть 100 объектов, из которых 95 принадлежат классу A, а 5 — классу B. Если наша модель классифицирует все объекты как класс A, точность будет равна 95%, хотя модель совершенно не учитывает объекты класса B.
Меткость
Представляет собой долю правильных классификаций модели:
Несложно увидеть, что сумма в знаменателе формулы представляет собой общее число классифицируемых примеров. Графически это можно интерпретировать следующим образом:
Рисунок 1. Меткость
В английском языке этот термин обозначается как «accuracy», поэтому в интернете он часто упоминается как «аккуратность», хотя это слово и не передает смыслового значения данной величины.
Несмотря на то, что эта мера хорошо интерпретируется, на практике она используется достаточно редко, поскольку плохо работает в случае дисбаланса классов в обучающей выборке.
Поясним это на примере кредитного скоринга. Пусть требуется классифицировать заемщиков на добросовестных (не допустивших просрочку) и недобросовестных (допустивших просрочку). Целью является выявление недобросовестных заемщиков, поскольку связанные с ними издержки выше. Следовательно, классификация заемщика как недобросовестного является положительным событием, а как добросовестного — отрицательным.
Выборка содержит 1000 добросовестных заемщиков, 900 из которых классификатор предсказал правильно (, ), и 100 недобросовестных, 50 из которых классификатор также определил верно (, ).
Несложно вычислить, что:
Однако, если построить «наивную» модель, которая просто будет классифицировать всех клиентов, как добросовестных (на основании того, что таковых большинство), то меткость такой модели окажется:
Таким образом, оказалось, что меткость «бесполезной» модели, не имеющей предсказательной силы, выше, чем «рабочей» модели. Это противоречит здравому смыслу. Поэтому на практике стараются использовать альтернативные меры качества.
Ключевых метрик для оценки эффективности опроса
Что это такое и почему важно
Отклик — это количество респондентов, которые действительно приняли участие в опросе, делая его результаты репрезентативными. Чем выше этот показатель, тем надежнее данные и тем точнее можно сделать выводы.
Примеры и кейсы из HR и маркетинга
Как улучшить эту метрику
2. Качество данных
Качество данных — это степень точности и полноты собранных ответов. Низкое качество данных может исказить результаты и привести к неверным выводам.
Пример из сферы социологических исследований
В исследовании общественного мнения может быть задан вопрос о доверии к государственным институтам. Если большинство ответов сосредоточены вокруг одного значения, это может указывать на низкое качество данных или на предвзятость опроса.
3. Время заполнения
Время заполнения опроса — это количество времени, которое респондент тратит на ответы на все вопросы. Эта метрика может быть индикатором уровня сложности опроса и вовлеченности респондентов. Слишком долгое время заполнения может отпугнуть участников, в то время как слишком короткое может указывать на недостаточную глубину исследования.
Пример из клиентского опыта
Предположим, вы хотите измерить уровень удовлетворенности клиентов после обращения в службу поддержки. Если опрос занимает 20 минут, большинство клиентов просто не будут его заполнять. Однако, оптимизация до 3-5 минут значительно повысит отклик.
Значение и методы измерения
Конверсия — это доля респондентов, которые не только начали заполнять опрос, но и завершили его. Эта метрика может служить показателем интереса и вовлеченности аудитории.
Пример из маркетинга
В контексте маркетинговой кампании, высокая конверсия может указывать на то, что ваш опрос привлекателен и актуален для целевой аудитории.
5. Уровень удовлетворенности от участия
Эта метрика отражает, насколько респонденты были довольны участием в опросе. Удовлетворенные респонденты скорее всего будут участвовать в будущих опросах, что повышает ценность и качество собранных данных.
Как измерить и улучшить
* после регистрации доступна демо версия для создания одного опроса и сохранения до 10 ответов
"Без данных вы просто ещё один человек с мнением". Это особенно актуально в контексте опросов, где качественный анализ данных может существенно повлиять на стратегические решения компании.
отмечал Джим Бергесон, эксперт в области аналитики данных
Мы рассмотрели пять ключевых метрик для оценки эффективности опросов: отклик, качество данных, время заполнения, конверсия и уровень удовлетворенности от участия. Каждая из этих метрик играет свою роль в формировании общей картины, и внимание к деталям здесь крайне важно.
Рекомендации для дальнейшего изучения метрик:
В заключение хочу сказать: даже самый креативно составленный опрос не принесет желаемых результатов, если не обратить внимание на эти метрики. Поэтому, дорогие коллеги, измеряйте, анализируйте и оптимизируйте. И тогда ваша работа принесет максимальную пользу!
Точность равна доле истинноположительных классификаций к общему числу положительных классификаций. Данная величина часто упоминается как positive predictive value (PPV) или положительное прогностическое значение:
Поясним данное выражение с помощью рисунка:
Рисунок 2. Точность
Несложно увидеть, что попытка отнести все объекты к одному классу неизбежно приведет к росту и уменьшению значения точности.
Технические метрики
метрик разработки программного обеспечения, на которые опираются программисты. Показатели, которые мы рассмотрим, важны также для контроля работы: обязательно запросите их у команды перед релизом.
Test Coverage
Плотность покрытия программного кода тестами — это процент кода, который проверили в ходе тестирования. Например, если этот показатель равен 78%, значит, 78% всего, что написали программисты, было проверено в ходе теста.
компании по разработке программного обеспечения метрика помогает понять:
Скорость загрузки страниц
Это крайне важная метрика разработки программного обеспечения — ведь скорость загрузки напрямую определяет жизнеспособность программы. Если страница будет долго грузиться, пользователь просто перестанет пользоваться приложением, а бизнес потеряет деньги. Слишком сложно написанный код, большое число редиректов, «тяжелый» мультимедийный контент — все это может пагубно сказываться на времени загрузки.
Поскольку оно зависит от множества факторов, то для измерения скорости обычно используют сразу несколько узконаправленных метрик. Среди них время:
метрикам разработки программного обеспечения можно сделать следующие выводы:
ER-диаграмма
ER-диаграмма — это схема базы данных. Она показывает, как различные элементы связаны между собой. Диаграмма состоит из простых геометрических фигур и линий между ними. В фигурах отражены «сущности» — объекты и понятия, а линии указывают на действия, которые выполняются между ними.

Диаграмма базы данных нужна, чтобы заказав услуги по разработке программного обеспечения, согласовать логику программы. Разработчики рисуют диаграмму на основе данных от заказчика.
Если с ней что-то не так, возможно:
Использование зрелого фреймворка
Фреймворк — это платформа с базовыми программными модулями, на которые затем «наращивают» приложение. Он задает архитектуру продукта. И как любой фундамент, фреймворк имеет важное значение для всей дальнейшей работы.
Сомнительный фреймворк, не подходящий под цели приложения, может обеспечить уйму проблем. А качественная платформа с поддержкой крупных компаний (например, Google или IBM) упрощает разработку, дает возможности и инструменты для высококлассной работы.
Хороший фреймворк дает следующие преимущества:
Проверка дублирования кода
Этот показатель важно проконтролировать при разработке программного обеспечения на заказ. Код с большим количеством повторений отдельных кусков считается низкокачественным: он занимает больше строк, требует больше времени на обработку. Соответственно, такой софт работает медленнее. Иногда код повторяют для упрощения процесса программирования, но зачастую это случайные повторы. Есть специальные сервисы, позволяющие автоматически выявить дублирование: в них загружают код, и система выдает, какие фрагменты повторяются. Один из них — Sonarqube
метрик разработки программного обеспечения гораздо больше, но большинству владельцев стартапов их трудно оценить без экспертизы в IT. Контроль этих метрик можно делегировать собственному техническому директору или сторонним специалистам — если вы выбираете аутсорсинг разработки программного обеспечения. А если вы планируете разобраться самостоятельно, наш перечень вам поможет. Но более понятной для бизнеса будет следующая группа показателей.
Среднеквадратичная ошибка — это сумма квадратов разностей между предсказанными и истинными значениями, деленная на количество объектов. Эта метрика широко используется для оценки качества регрессионных моделей.
MSE = (1/n) * ∑(ypred — ytrue)^2
Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Функция потерь в задачах классификации показывает, какую «цену» придется заплатить за неточность предсказаний классификационной модели. Для логистической регрессии, решающей задачу бинарной классификации, она может быть вычислена следующим образом:
Несложно увидеть, что функция потерь получается путем суммирования логарифма потерь на каждом примере. Потери на каждом примере определяются следующим образом: если предсказанный класс совпадает с фактическим, то потери равны 0, в противном случае потери равны 1. Очевидно, чем больше будет неправильных классификаций, тем больше будет значение LogLoss и тем хуже будет модель. Таким образом, чтобы получить лучшую модель, нужно минимизировать функцию потерь.
Преимуществом метрики LogLoss является устойчивость к выбросам и аномальным значениям в данных и простота вычисления. Недостатком — сложность интерпретации из-за нелинейного характера.
Коэффициент корреляции Пирсона
Коэффициент корреляции Пирсона используется для оценки качества регрессионных моделей. Он показывает степень линейной зависимости между предсказанными значениями и истинными значениями.
Значение данного коэффициента может варьироваться от -1 до 1, где -1 означает полную обратную корреляцию, 1 — полную прямую корреляцию, а 0 — отсутствие корреляции.
Метрики эффективности социальных сетей
Представление о результативности привлечения клиентов через соцсети дают такие показатели, как показы, CTR, CR и СРА. Спецификой этого канала продвижения является необходимость измерения объема пользовательской аудитории, уровня вовлеченности и охватов.
Количество подписчиков
Постоянное увеличение числа пользователей, подписавшихся на сообщество – хорошая тенденция. Однако само по себе растущее количество подписчиков не является доказательством эффективности рекламы. Эта метрика должна оцениваться как одна из составляющих общей картины. На сообщество могут быть подписаны пользователи, которые не относятся к целевой аудитории и никогда не станут вашими клиентами.
Изменение динамики количества постоянных читателей и зрителей – еще один важный параметр, позволяющий судить о том, интересен ли пользователям контент, после каких материалов происходят отписки, а какие подталкивают людей присоединиться к вашему каналу, группе, сообществу.
CPF – стоимость подписчика
С точным определением значения этой метрики могут возникнуть сложности, ведь пользователи приходят к вам не только благодаря таргетированной рекламе, а также через поисковики и рекомендации. И все-таки полезно наблюдать за динамикой показателя, чтобы подсчитывать расходы на привлечение новых пользователей.
В чистом виде эту метрику сложно посчитать, потому что подписчики приходят не только с таргетированной рекламы, но и органически – из поисковиков или рекомендаций. Тем не менее ее можно отслеживать в динамике, чтобы считать затраты на привлечение аудитории.
CPF = затраты на привлечение аудитории / количество подписчиков
ER – уровень вовлеченности
ER = сумма всех реакций / количество подписчиков*100 %
Кроме того, этот показатель дает информацию о доле активной аудитории, то есть о пользователях, регулярно взаимодействующих с сообществом. Если ER = 6,5, это значит, что только 6,5% подписчиков регулярно заходят на страничку, лайкают и репостят записи и выполняют другие действия.
Уровень вовлеченности можно измерять по нескольким формулам, каждая из которых предназначена для оценки по отдельным параметрам:
В зависимости от цели анализа, стоящей перед интернет-маркетологом, выбирается та или иная формула.
Логика развития метрик
Обычно о качестве машинного перевода судят, сравнивая его с неким эталоном (reference) – как правило, с переводом, выполненным человеком-переводчиком. На таком сравнении построено большинство существующих метрик, хотя и не все.
Глобально метрики качества машинного перевода можно подразделить на традиционные и нейросетевые.
Традиционные метрики сравнительно просты в расчете и прозрачны, наиболее известные из них разработаны до бума нейросетей. Чаще всего такие метрики основаны на подсчете числа совпадений символов / слов / cловосочетаний – их называют «lexic overlap metrics».
Большинство метрик, предложенных после 2016 года – нейросетевые. Первым шагом в применении нейросетей в расчете метрик стало использование векторных представлений слов (embeddings).
Сегодня наиболее используемые – метрики, предложенные до 2010 года, причем в 99% это BLEU.
Какие метрики качества используются для оценки алгоритмов машинного обучения
Узнайте об основных метриках качества для оценки алгоритмов машинного обучения, чтобы эффективно улучшать и оценивать свои модели!
Метрики качества играют важную роль в оценке алгоритмов машинного обучения, так как они позволяют определить, насколько хорошо модель работает на данных и какие улучшения ей требуются. В данной статье мы рассмотрим наиболее распространенные метрики качества, используемые для оценки алгоритмов машинного обучения.
F1-мера
Точность и полнота, в отличие от меткости, не зависят от соотношения классов и, следовательно, могут применяться в условиях несбалансированных выборок. На практике часто встречается задача поиска оптимального баланса между точностью и полнотой. Действительно, улучшая настройку модели на один класс, например, путем изменения дискриминационного порога, мы тем самым ухудшаем настройку на другой.
Чем выше точность и полнота, тем лучше модель. Но на практике их максимальные значения одновременно недостижимы, поэтому приходится искать баланс между ними. Для этого используется метрика, объединяющая в себе информацию о точности и полноте. Она называется F1-мера и вычисляется следующим образом:
В данном выражении точность и полнота имеют одинаковый вес, поэтому при их уменьшении -мера сокращается пропорционально.
Однако на практике чаще используется сбалансированная -мера, в которой точности и полноте присваиваются разные веса с целью найти оптимальный баланс между данными метриками. Для этого в формулу для -меры вводится дополнительный балансировочный параметр, обозначаемый . Сбалансированная -мера вычисляется следующим образом:
Если параметр принимает значения из диапазона 0< eta < 1, то приоритет имеет точность, а если , то полнота.
Еще одним источником критики -меры является отсутствие симметрии. Это означает, что она может изменить свое значение при инверсии положительного и отрицательного классов.