

- Почему энтропия вселенной растет?
- Что такое энтропия вселенной?
- Кто ввел понятие энтропии?
- Может ли энтропия вселенной уменьшиться?
- Находится ли вселенная в состоянии энтропии?
- О пи…сателях програмулин для государства (неайтишникам неинтересно)
- Существует ли предел энтропии во вселенной?
- Черные дыры и живые существа
- Энтропия как мера хаоса
- Энтропия: как деревья решений принимают решения
Почему энтропия вселенной растет?
Энтропия Вселенной будет продолжать расти, но что именно приводит к этому росту? Остаточные уровни излучения после Большого взрыва, ядерный синтез в звездах… Существует множество процессов, которые поддерживают поток энергии, но считается, что основной вклад в это вносят черные дыры из-за огромного количества частиц, которые они содержат.
Черные дыры обладают огромной концентрацией массы, которая обеспечивает им исключительно сильное гравитационное поле. Поэтому они допускают множественность микросостояний. В связи с этим Стивен Хокинг предположил, что черные дыры выделяют тепловое излучение вблизи своих горизонтов событий. Это излучение Хокинга может привести к потере массы и окончательному испарению черных дыр.
Но помните, что черные дыры подчиняются второму закону термодинамики, который гласит, что энтропия всегда будет иметь тенденцию к увеличению. Поэтому они будут набирать все большую массу и сливаться с другими черными дырами, превращаясь в сверхмассивные чёрные дыры.
А когда они в конце концов распадутся, излучение Хокинга, создаваемое распадающимися чёрными дырами, будет иметь такое же количество возможных состояний, как и сама ранее существовавшая черная дыра. Согласно этой точке зрения, ранняя Вселенная имела низкую энтропию из-за меньшего количества или гораздо меньших размеров черных дыр.
Что такое энтропия вселенной?
Хотя в физике это не одно и то же, полезно вспомнить о теории хаоса и о том, как она связана с энтропией, и, в конечном счете, какое влияние энтропия может оказывать на Вселенную.
Согласно теории хаоса, в кажущейся случайности хаотических, сложных систем есть скрытые закономерности и взаимосвязи. Если знать начальные условия и выяснить эти базовые закономерности, то можно предсказать нарушения, которые произойдут в будущем. Другими словами, хаос не так беспорядочен и случаен, как может показаться.
В своей самой простой формулировке энтропия определяется как мера тепловой энергии в системе на единицу температуры, которая не может быть использована для совершения полезной работы. Поскольку работа получается в результате упорядоченного движения молекул, энтропия также является мерой молекулярного беспорядка, или случайности, в системе.
Не только физика, но и многие дисциплины нашли применение этой концепции, включая химию, биологию, изменение климата, социологию, экономику, теорию информации и даже бизнес.
Но давайте остановимся на физике, а точнее, на фундаментальных законах термодинамики.
- Нулевой закон термодинамики – это закон теплового равновесия. Он гласит, что если две независимые системы находятся в тепловом равновесии с третьей системой, то они также находятся в тепловом равновесии друг с другом. Это означает, что если A = B и B = C, то A = C. Это легко наблюдать в реальной жизни. Например, когда вы подносите холодный стакан воды к горячему стакану воды. Они будут обмениваться теплом через диатермальную стенку, пока оба не достигнут теплового равновесия с температурой в комнате.
- Первый закон термодинамики – это применение закона сохранения энергии к термодинамическим процессам. Закон сохранения энергии утверждает, что энергию нельзя создать или уничтожить, а возможно только преобразовать или передать. В случае изолированной термодинамической системы это происходит за счет работы и тепла. Именно поэтому формула первого закона термодинамики имеет вид ΔU = Q – W, где ΔU – изменение внутренней энергии системы, Q – подведенное к ней тепло, а W – работа, которую система совершает над окружающей средой.
- Второй закон термодинамики также известен как закон энтропии, поскольку он вводит такое понятие, как уровень беспорядка в системе. Он обозначается буквой S. В каждом процессе есть определенное количество энергии, которое не может быть преобразовано в работу. Вместо этого она превращается в тепло. Тепло увеличивает беспорядок, или энтропию, изолированной системы. А поскольку всегда существует некоторая степень неиспользуемой энергии, которая превратится в тепло, второй закон термодинамики утверждает, что в изолированных системах всегда будет происходить увеличение энтропии. Изменение энтропии ΔS равно теплопередаче ΔQ, деленной на температуру T: ΔS =ΔQ / T.
- Третий закон термодинамики гласит, что энтропия системы приближается к постоянному значению по мере приближения температуры к абсолютному нулю. Если температура системы равна абсолютному нулю (нижний предел в термодинамической шкале температур), то энтропия также будет равна нулю.
Кто ввел понятие энтропии?
Несмотря на то, что понятие энтропии применяется в различных дисциплинах, оно берет свое начало в физике. Изучая сохранение механической энергии в своей работе ” Основные принципы равновесия и движения” (1803), французский математик Лазар Карно предложил, что ускорения и удары движущихся частей в машине представляют собой “потери момента активности”.
Другие ученые исследовали эту “потерянную” энергию, и в последней половине 19 века они указали, что это не настоящее исчезновение, а преобразование. Это и есть концепция сохранения энергии, которая проложила путь к первому закону термодинамики. Такие ученые, как Джеймс Джоуль, Юлиус Майер, Герман Гельмгольц и Уильям Томпсон (также известный как лорд Кельвин), опубликовали работы, исследующие эту концепцию.
Но термин “энтропия” появился в работах немецкого физика Рудольфа Клаузиуса, который сегодня считается одним из авторов термодинамики.
В 1850-х годах он представил изложение Второго закона термодинамики применительно к тепловому насосу. Заявление Клаузиуса подчеркивало тот факт, что невозможно построить устройство, работающее по циклу и не производящее никакого другого эффекта, кроме передачи тепла от более холодного тела к более горячему.
В 1860-х годах он придумал слово “энтропия” от греческого слова, означающего превращение, или поворотный пункт, для обозначения необратимой потери тепла. Он описал ее как функцию состояния в термодинамическом цикле, в частности в цикле Карно, теоретическом цикле, предложенном сыном Лазаря Карно, Сади Карно.
В 1870-х годах австрийский физик и философ Людвиг Больцман переосмыслил и адаптировал определение энтропии к статистической механике. Ближе к тому, что подразумевает этот термин сейчас, он описывает энтропию как измерение всех возможных микро-состояний в системе, макроскопическое состояние которой было изучено.
Она записывается формулой S = k ln Ω, где S – энтропия, K – постоянная Больцмана (1,38064852 × 10-23 м2 кг с-2 K-1), а Ω – количество, число возможных микросостояний.
Может ли энтропия вселенной уменьшиться?
Можно с уверенностью сказать, что энтропия во Вселенной в какой-то момент уменьшилась, потому что в ней существует определенный порядок. Гравитационные взаимодействия могут к примеру превращать туманности в звезды. Это своего рода порядок.
Энтропия может уменьшаться без нарушения второго закона термодинамики до тех пор, пока она увеличивается в других частях системы. В конце концов, второй закон термодинамики не говорит, что энтропия не может уменьшаться в определенных частях системы, а только то, что общая энтропия системы имеет естественную тенденцию к увеличению.
Находится ли вселенная в состоянии энтропии?
Еще в 19 веке Рудолф Клаузиус вывел, что энергия Вселенной постоянна, а ее энтропия имеет тенденцию к увеличению с течением времени.
Согласно наиболее широко принятой модели возникновения Вселенной, все пространство и время были созданы в результате Большого взрыва – события, произошедшего примерно 13,8 миллиарда лет назад. Согласно теории, до этого Вселенная была очень крошечной, очень горячей, плотной точкой, похожей на сингулярность, из которой возникло все, что мы видим вокруг себя.
По мнению космологов, затем эта точка “взорвалась”, расширяясь и распространяясь со скоростью, превышающей скорость света, и породив все частицы, античастицы и излучения во Вселенной.
Конечно, для этого должно было произойти огромное количество процессов связанных с изменением энтропии. Однако если мы подумаем о непрерывном увеличении энтропии, которое происходило на протяжении всех этих лет, то сможем сделать вывод, что энтропия Вселенной сейчас должна быть намного больше.
По мнению некоторых космологов, это можно объяснить с помощью идеи о существовании энтропии времени. Поскольку второй закон термодинамики гласит, что энтропия изолированной системы может увеличиваться, но не уменьшаться, энтропия требует определенного направления времени, иногда называемого осью времени. Таким образом, измерение энтропии – это способ отличить прошлое от будущего.
О пи…сателях програмулин для государства (неайтишникам неинтересно)
Существует ли предел энтропии во вселенной?
Как бы мы ни говорили о тенденции к увеличению энтропии, законы термодинамики также подразумевают состояние максимальной энтропии.
В повседневной жизни мы можем наблюдать это, когда наш кофе остывает в чашке. Когда кофе достигает комнатной температуры, это означает, что он находится в тепловом равновесии с окружающей средой. В кипящей воде, используемой для приготовления кофе, было много возбужденных атомов, но они замедлились и в конце концов достигли максимальной энтропии для данной системы.
Термодинамическое равновесие – это стабильное состояние, которое не обратимо без “помощи” – поступления энергии. Кофе нужно было бы подогреть, добавив энергию, например, поставив его на плиту или в микроволновую печь. Однако у нас нет никакого способа подать энергию во Вселенную после того, как она достигнет теплового равновесия. В конце концов, повсюду будут достигнуты одни и те же значения.
Черные дыры и живые существа
Со времен появления формулы Больцмана термин «энтропия» проник практически во
все области науки и оброс новыми парадоксами. Возьмем, к примеру астрофизику и пару «черная дыра — падающее в нее тело». Ее вполне можно считать изолированной системой, а значит, ее энтропия такой системы должна сохраняться. Но она бесследно исчезает в черной дыре — ведь оттуда не вырваться ни материи, ни излучению. Что же происходит с ней внутри черной дыры?
Некоторые специалисты теории струн утверждают, что эта энтропия превращается в энтропию черной дыры, которая представляет собой единую структуру, связанную из многих квантовых струн (это гипотетические физические объекты, крошечные многомерные структуры, колебания которых порождают все элементарные частицы, поля и прочую привычную физику).
Еще один парадокс, идущий вразрез со вторым началом термодинамики — это существование и функционирование живых существ. Ведь даже живая клетка со всеми ее биослоями мембран, молекулами ДНК и уникальными белками — это высокоупорядоченная структура, не говоря уже о целом организме. За счет чего существует система с такой низкой энтропией?
Энтропия как мера хаоса
Поскольку Клаузиус так и не смог сформулировать физический смысл энтропии, она оставалась абстрактным понятием до 1872 года — пока австрийский физик Людвиг Больцман не вывел новую формулу, позволяющий рассчитывать ее абсолютное значение. Она выглядит как S = k * ln W (где, S — энтропия, k — константа Больцмана, имеющая неизменное значение, W — статистический вес состояния). Благодаря этой формуле энтропия стала пониматься как мера упорядоченности системы.
Как это получилось? Статистический вес состояния — это число способов, которыми можно его реализовать. Представьте рабочий стол своего компьютера. Сколькими способами на нем можно навести относительный порядок? А полный беспорядок? Получается, что статистический вес «хаотичных» состояний гораздо больше, а, значит больше и их энтропия. Посмотреть подробный пример и рассчитать энтропию собственного рабочего стола можно здесь.
В этом контексте новый смысл приобретает второй закон термодинамики: теперь процессы не могут самопроизвольно протекать в сторону увеличения порядка. Но и тут не стоит забывать про ограничения закона.
Иначе человечество уже давно было бы в рабстве у одноразовой посуды. Ведь каждый раз, когда мы моем тарелку или кружку, нам на помощь приходит простейшая самоорганизация. В составе всех моющих средств есть поверхно-активные вещества (ПАВ). Их молекулы составлены из двух частей: первая по своей природе стремится к контакту с водой, а другая его избегает.
При попадании в воду молекулы «Фэйри» самопроизвольно собираются в «шарики», которые обволакивают частички жира или грязи (внешняя поверхность шарика это те самые склонные к контакту с водой части ПАВ, а внутренняя, наросшая вокруг ядра из частички грязи — это части, которые контакта с водой избегают).
Казалось бы, этот простой пример противоречит второму закону термодинамики. Бульон из разнообразных молекул самопроизвольно перешел в некое более упорядоченное состояние с меньшей энтропией. Разгадка снова проста: систему «Вода-грязная посуда после вечеринки», в которую посторонняя рука капнула моющего средства, сложно считать изолированной.
Энтропия: как деревья решений принимают решения

Вы специалист по Data Science, который сейчас идет по тропе обучения. И вы уже прошли долгий путь с того момента, как написали свою первую строку кода на Python или R. Вы знаете Scikit-Learn как свои пять пальцев. Теперь вы больше сидите на Kaggle, чем на Facebook. Вы не новичок в создании потрясающих случайных лесов и других моделей ансамбля деревьев решений, которые отлично справляются со своей работой. Тем не менее, вы знаете, что ничего не добьетесь, если не будете всесторонне развиваться. Вам хочется копнуть глубже и разобраться в тонкостях и концепциях, лежащих в основе популярных моделей машинного обучения. Что ж, мне тоже.
Сегодня я расскажу о понятии энтропии — одной из важнейших тем статистики, а позже мы поговорим о понятии Information Gain (информационный выигрыш) и выясним, почему эти фундаментальные концепции формируют основу того, как исходя из полученных данных строятся деревья решений.
Хорошо. А теперь преступим.
Что такое энтропия? Говоря простым языком, энтропия – это не что иное, как мера беспорядка. (Еще ее можно считать мерой чистоты, и скоро вы увидите почему. Но мне больше нравится беспорядок, потому что он звучит круче.)
Математическая формула энтропии выглядит следующим образом:

Энтропия. Иногда записывается как H.
Здесь pi – это частотная вероятность элемента/класса i наших данных. Для простоты, предположим, что у нас всего два класса: положительный и отрицательный. Тогда i будет принимать значение либо « », либо «-». Если бы у нас было в общей сложности 100 точек в нашем наборе данных, 30 из которых принадлежали бы положительному классу, а 70 – отрицательному, тогда p было бы равно 3/10, а p– будет 7/10. Тут все просто.
Если я буду вычислять энтропию классов из этого примера, то вот, что я получу, воспользовавшись формулой выше:
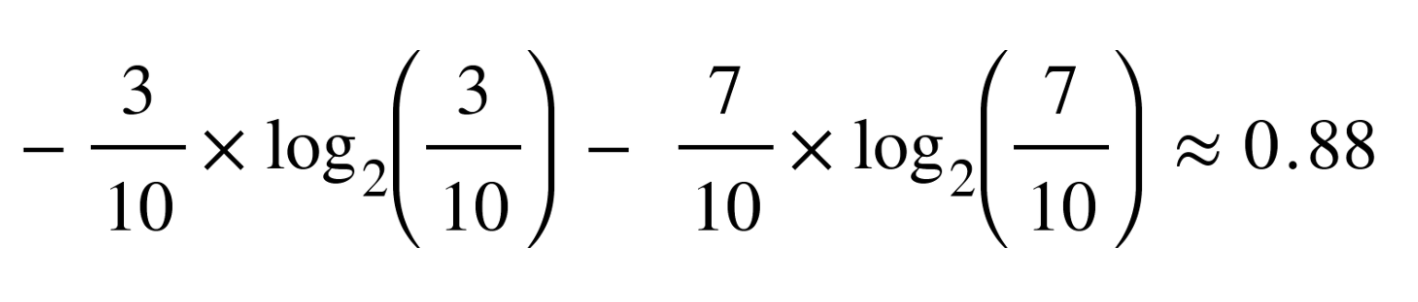
Энтропия составит примерно 0,88. Такое значение считается довольно высоким, то есть у нас высокий уровень энтропии или беспорядка (то есть низкое значение чистоты). Энтропия измеряется в диапазоне от 0 до 1. В зависимости от количества классов в вашем наборе данных значение энтропии может оказаться больше 1, но означать это будет все то же, что уровень беспорядка крайне высок. Для простоты объяснения в сегодняшней статье энтропия у нас будет находиться в пределах от 0 до 1.
Взгляните на график ниже.

На оси X отражено количество точек из положительного класса в каждой окружности, а на оси Y – соответствующие им энтропии. Вы сразу же можете заметить перевернутую U-образную форму графика. Энтропия будет наименьшей в экстремумах, когда внутри окружности нет положительных элементов в принципе, либо когда в них только положительные элементы. То есть, когда в окружности одинаковые элементы – беспорядок будет равен 0. Энтропия окажется наиболее высокой в середине графика, где внутри окружности будут равномерно распределены положительные и отрицательные элементы. Здесь будет достигаться самая большая энтропия или беспорядок, поскольку не будет преобладающих элементов.
Есть ли какая-то причина тому, что энтропия измеряется именно с помощью логарифма по основанию 2 или же почему энтропия измеряется между 0 и 1, а не в ином диапазоне? Нет, причины нет. Это всего лишь метрика. Не так важно понимать, почему так происходит. Важно знать, как вычисляется и как работает то, что мы получили выше. Энтропия – это мера беспорядка или неопределенности, а цель моделей машинного обучения и специалистов по Data Science в целом состоит в том, чтобы эту неопределенность уменьшить.
Теперь мы знаем, как измеряется беспорядок. Дальше нам понадобится величина для измерения уменьшения этого беспорядка в дополнительной информации (признаках/независимых переменных) целевой переменной/класса. Вот тут в игру вступает Information Gain или информационный выигрыш. С точки зрения математики его можно записать так:

Мы просто вычтем энтропию Y от X, из энтропии Y, чтобы вычислить уменьшение неопределенности относительно Y при условии наличия информации X об Y. Чем сильнее уменьшается неопределенность, тем больше информации может быть получено из Y об X.
Давайте рассмотрим простой пример таблицы сопряженности, чтобы приблизиться к вопросу о том, как деревья решений используют энтропию и информационный выигрыш, чтобы решить по какому признаку разбивать узлы в процессе обучения на данных.
Пример: Таблица сопряженности
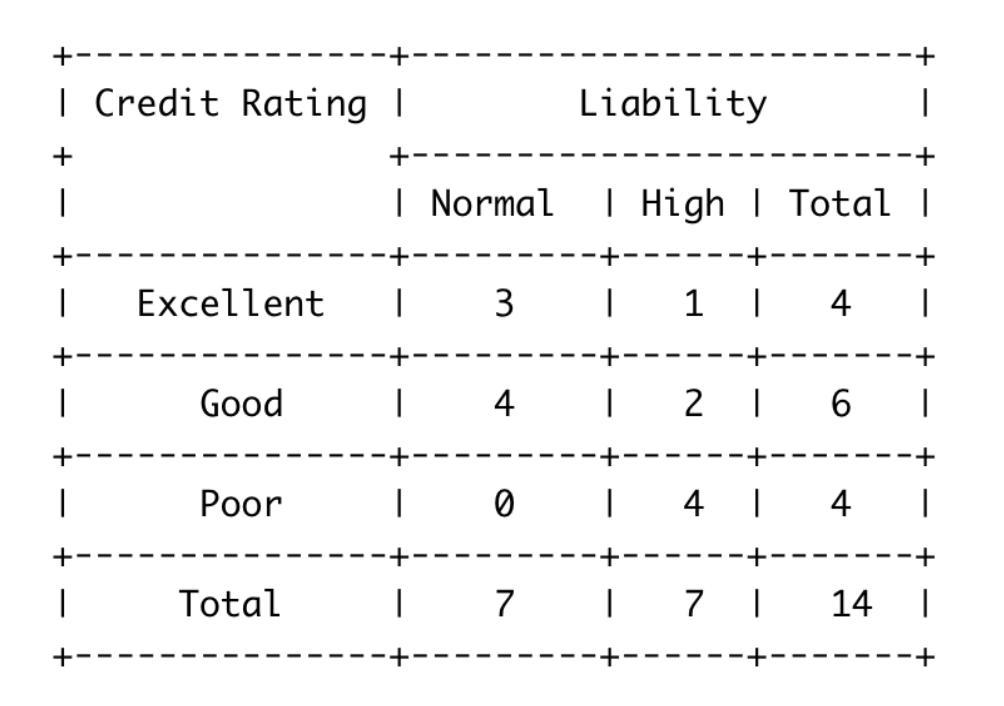
Здесь нашей целевой переменной будет Liability, которая может принимать всего два значения: “Normal” и “High”. Еще у нас есть всего один признак, который называется Credit Rating, он распределяет значения по трем категориям: “Excellent”, “Good” и “Poor”. Всего было сделано 14 наблюдений. 7 из них относятся к классу Normal Liability, и еще 7 к классу High Liability. Это уже само по себе разделение.
Если мы посмотрим на итоговую сумму значений в первой строке, то увидим, что у нас есть 4 наблюдения со значением Excellent по признаку Credit Rating. Более того, я даже могу сказать, что моя целевая переменная разбивается по “Excellent” Credit Rating. Среди наблюдений со значением “Excellent” по признаку Credit Rating, есть 3, которые относятся к классу Normal Liability и 1, которое относится к High Liability. Аналогично я могу вычислить подобные результаты для других значений Credit Rating из таблицы сопряженности.
Для примера я использую вышеприведенную таблицу сопряженности, чтобы самостоятельно вычислить энтропию нашей целевой переменной, а затем вычислить ее энтропию с учетом дополнительной информации признака Credit Rating. Так я смогу рассчитать сколько дополнительной информации мне даст Credit Rating для целевой переменной Liability.
Итак, приступим.
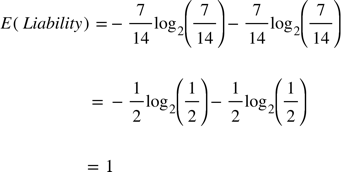
Энтропия нашей целевой переменной равна 1, что значит максимальный беспорядок из-за равномерного распределения элементов между “Normal” и “High”. Следующим шагом мы рассчитаем энтропию целевой переменной Liability с учетом дополнительной информации из Credit Rating. Для этого мы рассчитаем энтропию Liability для каждого значения Credit Rating и сложим их с помощью среднего взвешенного отношения наблюдений для каждого значения. Почему мы используем среднее взвешенное, станет яснее, когда мы будем говорить о деревьях решений.

Мы получили энтропию нашей целевой переменной с учетом признака Credit Rating. Теперь мы можем вычислить информационный выигрыш Liability от Credit Rating, чтобы понять, насколько этот признак информативен.

Знание Credit Rating помогло нам уменьшить неопределенность нашей целевой переменной Liability. Разве не так должен работать хороший признак? Давать нам информацию о целевой переменной? Что ж, именно по этой причине деревья решений используют энтропию и информационный выигрыш. Они определяют по какому признаку разбивать узлы на ветви, чтобы с каждым следующим разбиением приближаться к целевой переменной, а также, чтобы понять, когда построение дерева нужно завершить! (в дополнение к гиперпараметрам, таким как максимальная глубина, конечно же). Давайте посмотрим, как это все работает на следующем примере с использованием деревьев решений.
Пример: Дерево Решений
Давайте рассмотрим пример построения дерева решений, с целью предсказания того, будет ли кредит человека списан или нет. В популяции будет 30 экземпляров. 16 будут принадлежать классу “write-off”, а другие 14 к “non-write-off”. У нас будет два признака, а именно “Balance”, который может принимать два значения: “< 50K” или “>50K”, и “Residence”, который принимает три значения: “OWN”, “RENT” или “OTHER”. Я продемонстрирую, как алгоритм дерева решений будет принимать решение о том, какой атрибут разбить первым и какой признак будет более информативным, то есть лучше всего устраняет неопределенность целевой переменной с помощью использования концепции энтропии и информационного выигрыша.
Признак 1: Balance
Здесь кружки относятся к классу “write-off”, а звездочки – к классу “non-write-off”. Разбиение корня-родителя по атрибуту Balance даст нам 2 узла-наследника. В левом узле будет 13 наблюдений, где 12/13 (вероятность 0,92) наблюдений из класса “write-off”, и всего 1/13 (вероятность 0,08) наблюдений из класса “non-write-off”. В правом узле будет 17 из 30 наблюдений, где 13/17 (вероятность 0,76) наблюдений из класса “write-off” и 4/17 (вероятность 0,24) наблюдений из класса “non-write-off”.
Давайте вычислим энтропию корня и посмотрим, насколько дерево сможет уменьшить неопределенность с помощью разбиения по признаку Balance.

Разбиение по признаку Balance даст информационный выигрыш равный 0,37. Давайте посчитаем то же самое для признака Residence и сравним результаты.
Признак 2: Residence

Разбиение дерева по признаку Residence даст вам 3 узла-наследника. Левый узел-наследник получит 8 наблюдений, где 7/8 (вероятность 0,88) наблюдений из класса “write-off” и всего 1/8 (вероятность 0,12) наблюдений из класса “non-write-off”. Средний узел-наследник получит 10 наблюдений, где 4/10 (вероятность 0,4) наблюдений из класса “write-off” и 6/10 (вероятность 0,6) наблюдений из класса “non-write-off”. Правый узел-наследник получит 12 наблюдений, где 5/12 (вероятность 0,42) наблюдений из класса “write-off” и 7/12 (вероятность 0,58) наблюдений из класса “non-write-off”. Мы уже знаем энтропию узла-родителя, поэтому мы просто вычислим энтропию после разбиения, чтобы понять информационный выигрыш от признака Residence.

Информационный выигрыш от признака Balance почти в 3 раза больше, чем от Residence! Если вы снова взглянете на графы, то увидите, что разбиение по признаку Balance даст более чистые узлы-наследники, чем по Residence. Однако самый левый узел в Residence тоже достаточно чистый, но именно тут в игру вступает среднее взвешенное. Несмотря на то, что узел чистый, в нем меньше всего наблюдений, и его результат теряется при общем пересчете и вычислении итоговой энтропии по Residence. Это важно, поскольку мы ищем общую информативность признака и не хотим, чтобы конечный результат был искажен редким значением признака.
Сам по себе признак Balance дает больше информации о целевой переменной, чем Residence. Таким образом энтропия нашей целевой переменной уменьшается. Алгоритм дерева решений использует этот результат, чтобы сделать первое разбиение по признаку Balance, чтобы позже принять решение по какому признаку разбивать следующие узлы. В реальном мире, когда признаков больше двух, первое разбиение происходит по наиболее информативному признаку, а затем при каждом следующем разбиении будет пересчитываться информационный выигрыш относительно каждого дополнительного признака, поскольку он не будет таким же, как информационный выигрыш от каждого признака по отдельности. Энтропия и информационный выигрыш должны быть рассчитаны после того, как произойдет одно или несколько разбиений, что повлияет на итоговый результат. Дерево решений будет повторять этот процесс по мере своего роста в глубину, пока оно либо не достигнет определенной глубины, либо какое-то разбиение не приведет к более высокому информационному выигрышу за определенным порогом, который также может быть указан в качестве гиперпараметра!
Вот и все! Теперь вы знаете, что такое энтропия, информационный выигрыш и как они вычисляются. Теперь вы понимаете как дерево решений само по себе или в составе ансамбля принимает решения о наилучшем порядке разбиения по признакам и решает, когда остановиться при обучении на имеющихся данных. Что ж, если вам придется объяснять кому-то как работают деревья решений, надеюсь, вы достойно справитесь с этой задачей.
Надеюсь, вы извлекли что-нибудь полезное для себя из этой статьи. Если я что-то упустил или выразился неточно, напишите мне об этом. Я буду вам очень признателен! Спасибо.
Узнать подробнее о курсе.