

- Что такое trace
- Что такое observability?
- Live-кодинг
- Opencensus
- Opentelemetry
- Opentracing
- Базис наблюдаемости:
- В докладе
- Зачем нужен observability
- Как всё развивалось
- Как это все работает
- Как выполнить traceroute по порту
- Как использовать traceroute и tracert
- Как использовать traceroute по icmp
- Как работают tracert и traceroute
- Как установить traceroute на linux
- Кореляция логов между микросервисами
- Полезные ссылки
- Реализация распределенной трассировки с помощью корреляции логов и трейсов
- Россельхознадзор – нормативные документы
- Составляющие трейса
- Спецификации
- Трассировка
- Фитосанитарная въездная декларация ched-pp для стран евросоюза
- Заключение
Что такое trace
Вот несколько изображений, которые я украл из репозитория Jaeger, продукта, о котором я собираюсь рассказать. Предположим, что у нас есть 5 микросервисов, которые пронумерованы от A до E и которым присвоен какой-то уникальный идентификатор трассировки, чтобы помочь нам понять, как сообщение движется через нашу систему.
Когда сообщение поступает в вашу систему, скажем, в Nginx или веб-службу Microsoft, вы присваиваете ему GUID, а затем этот GUID используется в системе, пока вы не выясните его путь. Пути в конечном итоге связаны именно с этим.
Ваше сообщение будет проходить через систему в виде трека, который вы можете визуализировать. Как видно на рисунке, запрос прошел путь от A к B, затем к C, затем к D, а затем не закончил свое выполнение, пока не попал в E. Здесь мы видим поток времени слева направо, а также некоторые вложенные деревья вызовов.
Рассмотрим реалистичный пример.
После того, как запрос попадает куда-то в балансировщик, затем он попадает в API, из API он может попасть в кэш – если в кэше нет запроса, то он попадает в базу данных. Пример трассировки этого запроса показан ниже.
Я хотел бы отметить, что каждый из этих прямоугольников называется пролетом. “Пролет” обозначает некоторую операцию, в которой все, что после меня, выполнялось там дальше, после меня и после меня, заняло некоторое время. Длительность нашего запроса позволяет понять, сколько времени заняло его выполнение.
Балансировка открыла пролеты и передала запрос в API. После того как API открыл пролет, Cache передал запрос API. Он сказал, что у него нет никакого кэша. API отправил запрос в базу данных: “Хорошо, я посмотрю”. Во время запроса к базе данных я ответил: “Я закрываю свой пролет”, а затем передал запрос обратно балансировщику. Получив ответ, балансировщик сказал: “Ура, наконец-то я получил его” и вернулся к работе.
Наш запрос можно рассмотреть визуально в виде картинки. Наш запрос наглядно отображается, так как мы видим, сколько времени занял каждый шаг, куда он шел, как он шел и почему он шел.
Я должен добавить, что span существует на уровне компонента, репозитория, контроллера, а не только на уровне сервиса. Имея два сервиса, вы можете вызвать span в каждом методе и примерно увидеть, как запрос направляется в каждый сервис.
Что такое observability?

Наблюдаемость, или “Наблюдаемость распределенных систем” – Справочник
Наши системы должны быть прозрачными, чтобы быть наблюдаемыми. Наблюдаемость важна для понимания того, как работает система. Если ваша система работает непонятным образом, у вас есть метрики, следы, журналы, но вы не можете понять, что не так, значит, вам не хватает наблюдаемости.
Возможность мониторинга – это то, как подходить к разработке системы, как организовывать процесс тестирования, как организовывать процесс внедрения, как измерять и т.д. Это может показаться мониторингом, но это не так. И снова иллюстрация из этой замечательной книги:
Мы можем предотвратить предсказуемые падения с помощью мониторинга. В качестве примера, предположим, мы поставили метрики на падающие контроллеры, и мы поставили метрики на репозиторий. Очевидно, у нас там проблема, скорость падения запросов увеличилась, мы это увидели, все в порядке. Тестирование также замечательно тем, что мы можем предсказать отказ, проверить его, когда мы можем его предсказать.
У нас все еще есть множество проблем, которые мы не можем решить. Сообщения перемещаются асинхронно, происходят разрывы сети. Сообщение пришло не туда, сообщение пришло не туда, и мы сами зашли в тупик. Ниже приведен краткий обзор основных проблем за этот период времени.
Синий квадрат представляет все эти комбинации отказов, и наблюдаемость, по сути, охватывает этот синий квадрат. Разработчики рассматривают наблюдаемость как своего рода супермножество мониторинга. Она может быть причудливой и функциональной, но все равно основана на мониторинге.
Live-кодинг
Мне нужно завершить один простой проект.
Ссылка на мероприятие (16:22-17:18)
Он состоит из трех микросервисов. Каждая из них поставляется с простым контроллером. Что делают эти контроллеры? Они считают – 1, 2, 3. Вернув 1, микросервис 1 посылает запрос микросервису 2, соединяет запрос второго со словом “первый” и возвращается. Существует также микросервис 2, который выполняет ту же функцию, но возвращает слово “второй”. Третий микросервис выполняет то же самое, но возвращает слово “третий”.
Я хотел показать вам, как просто управлять Jaeger.
Ссылка на демонстрационный показ (17:18-18:34)
Нам часто бывает трудно начать использовать что-либо, особенно когда речь идет об инфраструктуре или развертывании чего-либо.
Однако мы постоянно сталкиваемся с проблемой, что начало использования чего-либо может занять до двух дней. Jaeger можно запустить, просто выполнив команду docker run. Команда, которую я создал, приведена в readme, в официальной документации DotNext и в репозитории, который я создал для нее.
С помощью этой команды можно собрать все компоненты Jaeger из образа. Поскольку он полностью модульный, доступно несколько образов Docker. Команда, подобная этой, запускает образ docker, предоставляя нам готовое к использованию решение.
На моем нынешнем рабочем месте мы делаем вот что: у нас есть специальный файл ssh под названием SSH monitor. Мы запускаем его, он посылает нам метрики и запускает Jaeger, который хранит все данные в нашей памяти, а когда он умирает, мы перезапускаем его и все. Для местного развития этого более чем достаточно.
Ссылка на демонстрацию (18:34-19:14)
Для различных вариантов отправки трассировки требуются все эти порты. Jaeger также имеет эту функцию, но как только у них возникла проблема с Zipkin, они реализовали обратную совместимость с Zipkin. Они говорят, что если у вас есть Zipkin в вашей инфраструктуре, вам не нужно ничего делать, просто переключите трафик на Jaeger, и все будет работать.
Давайте запустим этот файл. Я уже загрузил изображение. Оно запускается и занимает около 30 секунд для загрузки, так что оно не очень большое.
Ссылка на демонстрацию (19:14-19:32)
В readme я специально указал адрес, где мы можем найти трассировку. Давайте воспользуемся им.
Ссылка на демонстрацию (19:32-20:00)
Как уже упоминалось, мы работаем над замечательным пользовательским интерфейсом, которого у нас сейчас нет по практическим причинам. Мы еще ничего не отгрузили, но на данный момент это, по сути, способ просмотра трасс по умолчанию. Программа позволяет нам выбирать несколько сервисов, выбирать определенную транзакцию, фильтровать материал, искать и так далее.
Для запуска решения я написал отдельный файл без всякой магии в нем. Предыдущий запуск убивается, так как было запущено что-то другое, и наши первое, второе и третье решения просто запускаются.
Ссылка на демонстрацию (20:00-20:49)
Мы видим прекрасный релиз скрипта, видим, что я где-то написал async и забыл await, все в порядке. А теперь запускается . NET. Мы видим, что все запускается.
Давайте попробуем послать запрос.
Связь с демонстрацией (20:49-21:10)
Curl – самый простой API, который можно использовать для этого. Первый, второй и третий запросы прошли через систему, теперь давайте посмотрим, что произошло с Jaeger.
Когда у нас было три микросервиса в Jaeger, мы могли посмотреть, чем они занимаются.
Ссылка на демонстрацию (21:10 – 23:11)
Наш запрос занял около 500 миллисекунд. Давайте повторим его.
Jaeger показывает, что один запрос занял 500 миллисекунд, а второй – 16 миллисекунд. Давайте повторим это в третий раз.
Запросы выполняются все быстрее и быстрее. Начальные запросы самые длинные, затем все остальное идет быстрее. Я собираюсь пройтись по запросу и посмотреть, что он говорит. Эти штуки в основном отображают полный жизненный цикл одного запроса. Когда я запускаю запрос get, он проходит через систему, проходит через микросервисы и возвращается – теперь каждый запрос отображается в пользовательском интерфейсе.
Давайте опустимся и посмотрим на общую картину с размаха.
Мы видим, что у нас есть запрос типа get, он пришел в первый микросервис, выполнил какие-то действия, потом он пошел во второй микросервис, выполнил какие-то действия, пошел в третий микросервис запустился, вернул какие-то действия, написал какие-то логи, причем достаточно подробные, это одна из особенностей библиотек, которые подключаются. Затем мы получили результат обратно.
Ни в одном из запросов не было параллельных запросов; мы прошли первый, затем второй, затем третий.
Мы рассмотрим еще одну функцию Jaeger, которая называется построением графа зависимостей ваших микросервисов. Три узла образуют небольшой граф.
Ссылка на события (23:11-23:59)
Если мы спроецируем его на нашу обычную основу, то увидим, что запросы сначала поступают в первый микросервис в количестве трех штук, затем попадают во второй микросервис в количестве трех штук и, наконец, достигают третьего микросервиса. Это здорово, что мы можем построить карту наших микросервисов и увидеть, как запросы перемещаются через них.
Давайте обратимся к коду и посмотрим, как я все это подключил. Давайте запустим Startup.c.s первого проекта, чтобы сделать это.
Ссылка на показ (23:59-26:00)
Для того чтобы Jaeger работал, нам нужны два набора библиотек или две библиотеки. Во-первых, Jaeger, а во-вторых, OpenTracing.
В нашем проекте подключается OpenTracing, и регистрируется интерфейс Tracer, который помогает нам строить эти трассы. Используя библиотеку Jaeger, мы создаем трассировщик, соответствующий имени приложения, и регистрируем его глобально.
S P Dependency Injection Registration, поскольку это регистрация ASP. Может существовать некоторый код, для которого мы также хотим использовать трассировку и для которого у нас нет инжектора. Для этого у нас есть статические классы. Мы возвращаем реализацию и используем ее.
Для ASP AddOpenTracing добавляет обработчики протоколирования. NET Core. Мы добавляем логи для ASP. NET Core, для CoreFX, для EntifyFrameworkCore и так далее. Единственное, что вам нужно сделать, чтобы все эти трассировки работали, – это запустить Docker run и код, который я предоставил.
Несмотря на то, что в первый раз поиск документации занял у меня около 30 минут, все прошло отлично.
Opencensus
В это время в этой же галактике существовала такая компания, как Google. В своих внутренних продуктах компания использовала библиотеку OpenCensus, которую в определенный момент тоже заопенсорсила.
Открытая перепись – Enlace
Это проект с открытым исходным кодом, основная миссия которого – упростить работу с метриками и предоставить разработчикам трассировки. Наши авторы понимают: у нас так много провайдеров, у нас так много вещей, мы просто хотим быть проще.
Вам необходимо использовать библиотеку OpenCensus. Мы также предоставляем унифицированный интерфейс, который позволяет подключаться к различным провайдерам.
Вот пример того, как работает эта библиотека. Это выглядит так же, как и при использовании OpenTracing. У нас есть что-то вроде SpanBuilder, что-то, с чего мы начинаем, что-то, что мы делаем, и т.д.
Спецификация OpenCensus — Ссылка
Я думаю, что реализация работает примерно так же: у нас есть наше приложение, под ним есть несколько интерфейсов, мы взаимодействуем с этими интерфейсами, данные отправляются, и мы вообще не беспокоимся об этом.
Также доступна реализация OpenCensus. Хотя OpenTracing состоит только из интерфейсов, OpenCensus служит реализацией интерфейса. Он предлагает трассировки, а также метрики. Мы видим, что экспортеры для Azure, для Prometheus и для Jaeger реализованы на C#.
Слева от кольца находится OpenCensus, который работает с интерфейсами и реализациями, а справа – OpenTracing, работающий только с интерфейсами.
Я просто привел сравнение, чтобы вызвать интерес.
OpenCensus и OpenTracing имеют интерфейс ITracer. Они выполняют одно и то же действие и даже возвращают один и тот же интерфейс с точки зрения имени. Их функции немного отличаются, но все они выполняют одну и ту же роль.
SpanBuilder и ISpan являются одним и тем же.
При некоторых незначительных различиях оба решения достигают примерно одного и того же. Им удалось договориться благодаря тому, что ребята, поддерживающие эти проекты, работают в крупных компаниях. На нейтральной территории где-то в Сиэтле между кампусами Microsoft и Google они решили работать над проектом под названием OpenTelemetry.
Opentelemetry

Вот скриншот старого сайта. Сейчас их сайт выглядит гораздо лучше. Проект OpenTelemetry – это кульминация двух различных усилий, которая берет лучшие черты OpenTracing и OpenCensus и объединяет их в проект OpenTelemetry.
Чтобы облегчить вашу жизнь при работе с трассировками и метриками в ваших приложениях, OpenTelemetry здесь, чтобы помочь, разработать библиотеку, решение. Это означает, что вам нужно подключить только одну библиотеку.
OpenTelemetry – это репозиторий на GitHub, в котором есть несколько реализаций.
На данный момент реализация OpenTelemetry на C# является одной из самых передовых на планете.
По сравнению со всеми другими языками, он развивается более быстрыми темпами. Microsoft активно продвигает его, и он активно развивается.
Notes: OpenTelemetry .NET SIG — Ссылка
Развитие открыто, и каждую неделю проводятся ежедневные митинги. Microsoft прислушивается к сообществу, а сообщество прислушивается к Microsoft. Рано или поздно эта библиотека будет выпущена.
Прогрессия текущей ГИС – Ссылка
Моя личная история с этой библиотекой – одна из двух интересных историй, связанных с этой библиотекой.
Во-первых, релиз OpenTelemetry должен был состояться в ноябре, но они объявили: “Упс, мы не рассчитали, мы попробовали что-то, мы попробовали что-то, это не сработало, ждите следующего года”. Этот релиз выйдет в третьем квартале 2020 года, исходя из того, что они написали в чатах и в выпуске.
Моя вторая история связана с личным опытом работы с OpenTelemetry.
Альфа-версии OpenTelemetry уже доступны. Это было похоже на “Ура, я выпускаю альфа-версию”. Документация пакета не соответствует документации мастера, и релиз состоялся в июне, после чего прошло шесть месяцев разработки.
Нашим первым шагом должно стать подключение к альфа-каналу, сборка альфа-пакета new get из ночных сборок или локальная сборка. Как только они опубликуют следующий релиз, у меня будут все шансы опробовать его. Я мучился целый вечер, а потом сдался.
Самое главное, что мы все будем там. Каждый, кто использует OpenTracing или OpenCensus, рано или поздно будет использовать OpenTelemetry.
Если вы хотите отслеживать свой проект, OpenTracing теперь имеет больше смысла. По крайней мере, для . Они приняли API OpenTracing, немного переименовали их и импортировали несколько API и экспортеров OpenCensus.
Opentracing
Когда я показывал, как Jaeger можно подключить к проектам, я объединил две библиотеки: Jaeger и OpenTracing.
Представьте себе абстрактный контроллер, плавающий в вакууме, ASP. NET Core. Мы можем внедрить в него какой-нибудь репозиторий, а затем изменить способ реализации базы данных. Предположим, мы пишем репозиторий, потом нам надоедает схема SQL или мы переносим нашу базу данных в облако, тем временем мы меняем реализацию, и все работает.
Именно в этом и заключается суть OpenTracing. Трассировка – это набор интерфейсов, абстракция, которая помогает нам работать с распределенной трассировкой.
По ее словам, “я даю вам интерфейс, вы используете его и не парьтесь, потому что вы – конечный пользователь, а где-то там вы подключаете библиотеку и можете легко изменить реализацию span на другого поставщика”.
Наша библиотека и интерфейсы связаны. Сейчас мы используем Jaeger, нам дали денег, и мы решили интегрировать DataDog. В коде ничего переписывать не пришлось, только некоторые сложности с настройкой, чтобы все это подключить.
Эта спецификация реализована в виде набора интерфейсов. Ее используют несколько языков, включая . Net, все это есть на GitHub, и проект действительно довольно прост.
Фреймворк содержит набор интерфейсов и несколько вспомогательных утилит, таких как iTracer, iSpan, инкапсулирующий работу с пролетами, интерфейсы для SpanBuilder, позволяющие создавать пролеты, а также несколько интерфейсов, связанных с диапазонами.
Вот пример этого
Я использую iTracer, я использую его как-то.
public interface ITracer
{
…
ISpanBuilder BuildSpan(string operationName);
…
}Как часть интерфейса iTracer, определенный метод BuildSpan принимает строку и возвращает другой интерфейс под названием IBuildSpan.
Начало конференции
Интерфейс ISpanBuilder включает:
public interface ISpanBuilder
{
…
ISpan Start();
…
}У интерфейса есть метод, который возвращает интерфейс.
Эти методы вызываются на следующих интерфейсах. ISpan – это часть интерфейса, которая также определяет некоторые методы для себя. А теперь обязательный финиш, который вы должны запомнить.
public interface ISpan
{
ISpan SetTag(string key, bool value);
ISpan Log(string @event);
void Finish();
}
Работаем через интерфейс: инкапсуляция, полиморфизм — вот это всё, что мы любим или не любим.
Интерфейс возвращает интерфейс, интерфейс, интерфейс. Работа максимально высокоуровневая, и мы не знаем, что происходит в бэкенде, мы счастливы.
Подключить реализацию так же просто, как указать нашему провайдеру на реализацию, создавшую вам совместимость с OpenTracing.
Это набор интерфейсов с открытым исходным кодом на GitHub, с помощью которых различные создатели и поставщики Trace могут работать совместно.
Как только Джагер узнала об OpenTracing, она сказала: “О, мои библиотеки будут совместимы с OpenTracing”. DataDog поступает точно так же.
Я нашел 4 провайдера OpenTracing для провайдеров . NET. Instana, DataDog, Jaeger, LightStep и Jaeger уже довольно часто упоминались.
LightStep можно подключить, чтобы просто изменить реализацию. Опции и все. В нашей реализации мы просто изменили интерфейсы и изменили реализацию где-то в бэкенде.
Базис наблюдаемости:
Данная статья посвящена двум аспектам наблюдаемости: журналам (только тем, которые генерируются приложением) и трассировкам.
В докладе
Теперь докладчик расскажет историю.
Пока мы говорим о наблюдаемости, о том, зачем она нужна, о распределенных метках отслеживания, о Jaeger, системе для сбора меток отслеживания, я собираюсь рассказать о том, как в Санта-Барбаре разворачивались события вокруг OpenTracing и OpenCensus, и чем все это закончилось.
Наш мир с каждым днем становится все более сложным. В тысячах изображений есть красивый фронтенд и ужасный бэкенд, но чаще всего пользователи видят только верхушку айсберга.
Я нашел прекрасную фотографию . NET.
Изображение представляет собой наш ход времени. Картинка из 2021 года, но по сути ничего не изменилось. В 2005 году у нас было классическое распределенное приложение, с которым я столкнулся в начале своей работы. У нас есть веб-сервер, база данных, логика, мы ходим, раздаем их, все довольны.
Сейчас это не работает. Микросервисы становятся все более популярными, люди хотят быть модными, и множество других вещей увеличивают рабочую нагрузку.
Раньше у нас было классическое приложение, которое представляло собой один двоичный файл, распространенный максимум на двух машинах, и мы были довольны этим.
Вместо этого нам пришлось иметь дело с микросервисами, что стало еще сложнее. Предположим, у нас есть система, состоящая из нескольких компонентов. Наличие большего количества компонентов увеличивает количество точек отказа.
Потом у нас есть эти ребята.
Хотя они новые, они добавляют еще один уровень абстракции. Он загружается в докер, мы его куда-то отправляем, он крутится, и что-то происходит. Что с этим делать – непонятно.
Мы постоянно увеличиваем сложность наших систем и добавляем дополнительные компоненты. Различные типы сложных систем обладают достаточно широким набором проблем, которые можно разделить на категории.
Проблемы присущи любой сложной системе. Чем больше вы делаете, тем больше вы можете сломать. Распределенные системы ведут себя непредсказуемо. Здесь используется комбинаторика, а именно, комбинации сбоев могут накладываться друг на друга.
Формула для расчета комбинаций отказов. Просто посчитайте, сколько у вас микросервисов, и вы узнаете примерно, сколько комбинаций отказов может быть.
Это означает, что мы не всегда можем предсказать, какие сбои произойдут вместе. Это самое страшное. В моей практике этот момент причинял мне сильную боль в течение очень долгого времени. Это когда вы думаете: “Да, я написал это, это работает – так круто! “.
Как только вы даете ему протестировать, а затем проверяете журналы и метрики через 3 дня, вы понимаете, что одно сообщение пришло раньше другого на 2 миллисекунды, что вызвало сбой.
Бизнес-услуги – это то, чем мы занимаемся, поэтому мы делаем так, чтобы бизнес чувствовал себя хорошо. За это бизнес платит деньги. Крайне важно выяснить, как починить наши системы. Она не работает или работает не так, как ожидалось.
Зачем нужен observability
Пример немножко абстрактный, реальный код пойдёт чуть позже.
Микросервисы – демонстрация – ссылка
Фотография репозитория Google Cloud Platform, демонстрирующая демонстрацию микросервисов. Присутствует около 8 языков . NET.
Возможно, сообщение ушло куда-то не туда. Нам нужен способ быстро определить, не работает ли CurrencyService, EmailService или что-то еще. В этом случае нам нужно диагностировать проблему.
Кроме того, вы можете просмотреть журналы (grep – это утилита Linux, позволяющая искать текст). Моя нынешняя работа также прошла через этот этап. Когда у нас есть распределенная система, мы такие: “Конечно, журналы будут полезны”. Через два дня вы понимаете, что не получили ни большего, ни равного с меньшим, поэтому вы сидите и сидите, сидите и сидите.
Электронный магазин – Enlace
Казалось бы, никто не любит Google – вот картинка из репозитория Microsoft, демонстрирующая нечто подобное. Помимо некоторых микросервисов, у нас есть мобильные приложения, веб-магазины и т.д. И если что-то сломалось, как мы узнаем?
Для того чтобы разработчики могли предсказать все это и повысить наблюдаемость системы, существует три столпа, а именно: журналы, метрики и трассировки.
Как всё развивалось
В 2021 году компания Google опубликовала работу под названием Dapper, в которой описывается масштабируемая система распределенных меток трассировки. Это не Dapper, не ORM, а метрики.
Как это все работает
На самом деле все работает примитивно.
Создаются запросы, вместе с ними загружается информация, описывающая запрос, и мы отправляем его на бэкэнд. Когда запрос приходит к первому микросервису, у которого включен Jaeger, и в вашем коде включен Jaeger, проверяется заголовок. Если в заголовке есть идентификатор трассировки, Jaeger разбирает его, если нет, то создает его.
Мы получаем все наши запросы с идентификатором заголовка, строкой примерно из 16 символов, которая является хэшированной строкой. После того как запрос попадает на вход, на выход, а затем в коллектор, отдельная библиотека помогает отобразить все это в бэкенде.
В структуре Jaeger есть 4 основные части. Клиентская часть, часть коллектора, часть базы данных и часть пользовательского интерфейса.
Вы включаете в свое приложение некоторый код (включаете библиотеку), содержащий информацию о пролетах в Agent.
Он отправляет UDP-сообщение агенту, который может быть установлен либо рядом с вашим sidecar в Docker, либо на той же машине, что и ваш sidecar. Сообщение отправляется по UDP, через быстрый loopback, и клиентское приложение почти не загружено – таким образом, при отправке span-items не возникает проблем с производительностью.
Затем Jaeger-agent отправляет его коллектору через gRPC.
Он сортирует, складывает данные и работает с ними, то есть в него поступает поток данных, а он сливает их в базу данных. С другой стороны, коллекторы могут использоваться для хранения настроек, удаленных от устройства.
Как только службы подключаются к коллектору, они считывают настройки и работают над ними. Сейчас идет работа над адаптивными настройками, так что объем получаемого вами пространства будет меняться в зависимости от вашего трафика.
На самом деле в Uber есть проблема; я знаю несколько российских компаний, которые столкнулись с той же проблемой: когда у вас много пролета, вам нужно много железа.
Для этого и существует выборка. Нет необходимости отправлять каждый пролет и каждый след в бэкэнд Jaeger. Вы можете отправлять их снова и снова, и он сохранит каждую сотую или тысячную. В результате они прилагают все усилия, чтобы сделать выборку адаптивной и приспосабливаемой к изменяющимся условиям.
Следующая часть – DB.
Как выполнить traceroute по порту
U DP-пакет по умолчанию отправляется на порт 34434 и увеличивается на 1 на каждом узле: 34434 на первом узле, 34435 на втором и так далее. Ручной порт может быть указан с помощью ключа -p. Вот как будет выглядеть команда:
Traceroute -p [числовой порт] домен.имя
Указанный порт нельзя отследить стандартными средствами в Windows, так как Traceroute в cmd не существует, а Tracert не умеет работать с портами.
Как использовать traceroute и tracert
Пожалуйста, сделайте снимок экрана или скопируйте вывод команды, если вам нужно отправить его в службу поддержки.
Как использовать traceroute по icmp
Traceroute использует протоколы UDP и ICMP. По умолчанию используется UDP. Чтобы использовать ICMP, добавьте к команде ключ -I:
traceroute -I domain.name
Для чего это нужно? Оборудование может не отвечать на такие запросы. Видеть * в выводе означает, что маршрутизатор отклонил пакет и не ответил.
Попробуйте использовать в этом случае ключ -I:
Ключ -I требует привилегий root. Для команд, которые не выполняются, добавьте sudo:
sudo traceroute -I domain.name
Трассировка используется для диагностики проблем сети. Её может запросить ваш хостинг- или интернет-провайдер. В этом случае предоставьте скриншот или текст вывода команды.
Если сайт работает, а трассировка до него не доходит, значит запросы фильтруются на пути к цели. Отсутствие трассировки не означает наличие проблемы.
Как работают tracert и traceroute
При открытии сайта браузер пользователя отправляет сообщение (запрос) на сервер, где находится сайт. Для передачи сообщения используются маршрутизаторы. Сообщение отправляется туда, где, по их мнению, оно достигнет цели.
Маршрутизаторы (хопы) или узлы обычно называются хопами в режимах трассировки. Если вы используете Tracert и Traceroute, вы можете увидеть, через сколько узлов проходит запрос. Эти узлы называются транзитными, поскольку они не являются целью запроса.
Traceroute создает UDP-датаграмму (сообщение, которое должно быть доставлено на целевой сервер), упаковывает ее в IP-пакет и передает первому транзитному узлу. Заголовок содержит поле TTL – продолжительность жизни пакета.
Ip-адрес определяет количество переходов, которые может преодолеть пакет. На каждом переходе TTL уменьшается на единицу. Когда время жизни пакета достигает 0, маршрутизатор отбрасывает его и возвращает источнику сообщение об ошибке ICMP с заголовком “Время превышено”.
Эти две утилиты основаны на одном и том же принципе, но между ними есть некоторые различия. Давайте рассмотрим каждую утилиту в отдельности.
Как установить traceroute на linux
В Unix-подобных средах он может быть не установлен. В этом разделе показано, как установить Traceroute в некоторых различных операционных системах.
Кореляция логов между микросервисами
Когда журнал большого распределенного приложения регистрируется централизованно, он может получать десятки гигабайт данных каждый час. Поскольку запрос может проходить через несколько микросервисов, один из способов получить все журналы, относящиеся к запросу, охватывающему несколько микросервисов, – это присвоить каждому запросу уникальный идентификатор (id).
Полезные ссылки
Ниже представлен список литературы, который Егор настоятельно рекомендует к ознакомлению:
До следующей конференции DotNext 2020 Piter осталось меньше недели! На этой конференции выступят Скотт Хансельман, Джон Скит и многие другие известные докладчики. Вы также можете приобрести абонементный билет, который позволит вам посетить все 8 конференций этого сезона.
Реализация распределенной трассировки с помощью корреляции логов и трейсов
#1: Используйте сторонние решения, такие как DATADOG, для автоматизации процесса
Ссылка: DataDog APM
Мы используем DataDog APM (мониторы производительности приложений) для измерения сервисов в распределенных системах. Помимо отслеживания 100% всех запросов, Datadog также может собирать журналы, генерируемые вашим программным обеспечением.
Основная функция Datadog заключается в централизованном протоколировании и отслеживании информации. Идентификатор трассировки Datadog генерируется и автоматически распространяется на нижележащие микросервисы. Используя только DD traceId, мы можем соотнести журналы и трассировки.
ПОДХОД #2: ZIPKINS, CLOUD-SLEUTH СО SPRING BOOT
Ссылка :
Ципкинс, искатель облаков
Преимущества
- Полная интеграция с загрузкой SPRING
- Простота в использовании
- Возможность визуализации треков с помощью пользовательского интерфейса Zipkins.
- Поддержка стандартов OpenTracing с использованием внешних библиотек.
- Поддержка корреляции журналов с использованием контекстов Log4j2 MDC.
Недостатки:
- Не существует решения для автоматического сбора связанных с отслеживанием файлов журналов. Мы должны сами отправлять журналы в ElasticSearch и искать их, используя идентификаторы трасс, сгенерированные cloud-sleuth (например, заголовок X-B3-TraceId).
Дизайн:
МЕТОД 3: РЕНТГЕНОВСКИЙ СНИМОК АМАЗОНИИ
Ссылка: AmazonXRAY
Преимущества:
- Поддерживает все ресурсы AWS, что очень удобно, если ваши распределенные службы развернуты и работают на AWS
- Балансировщики нагрузки AWS автоматически генерируют идентификаторы REQUEST ID для каждого входящего запроса, освобождая ваше приложение от этой обязанности. (Ссылка)
- Позволяет отслеживать весь путь от шлюза API до балансировщика нагрузки, сервиса и других ресурсов, зависящих от AWS
- Вводит корреляцию журналов с журналами CLOUDWATCH
Обратная сторона медали:
- Журналы Cloudwatch могут стать очень дорогими при большом объеме журналов.
ПОДХОД #4: JAGER
Ссылка : Джагер
Преимущества:
- Поддерживает opentracing по умолчанию
- Имеет библиотеки, работающие с Spring
- Поддерживает Jager Agent, который можно установить в качестве инструмента для трассировки и распространения логов.
Недостатки:
Сложная инфраструктура требует довольно длительного обслуживания и настройки.
Россельхознадзор – нормативные документы
Территориальные отделы. Кавказское межрегиональное управлениеСеверо-Западное межрегиональное управлениеСеверо-Кавказское межрегиональное управлениеСевероморское межрегиональное управлениеТу для Алтайского края и Республики АлтайТу для Амурской областиТу для Брянской, Смоленской и Калужской областейТу для Владимирской области, Костромской и Ивановской областейТу для Воронежской, Белгородской и Липецкой областейТу для Москвы, Москвы и Тульской областиТу для Забайкальского краяТу для Иркутской области и Республики БурятияТу для Калининградской областиТу для Камчатского края и Чукотского регионаТу для Кировской области, Удмуртской Республики и Пермского краяТУ для Красноярского краяТУ для Нижегородской области и Республики Марий ЭлТУ для Новосибирской областиТУ для Оренбургской областиТУ для Орловской области и Курской областиТУ для Приморского края и Сахалинской областиТУ для Республики Хакасия, Тыва, и Кемеровской области – КузбассТУ для Республики БашкортостанТУ для Республики Мордовия и Пензенской областиТУ для Республики Саха (Якутия)ТУ для Республики ТатарстанТУ для Ростовской области, Республика Башкортостан ТТУ для Республики Мордовия и Пензенской области ТТУ для Республики Саха (Якутия)ТТУ для Республики Татарстан ТТУ для Республики Ростов, Ростовской области, Волгоградской и Астраханской областей, Республика Калмыкия ТТУ для Рязанской и Тамбовской областей ТТУ для Саратовской и Самарской областей ТТУ для Свердловской области ТТУ для Тверской и Ярославской областей ТТУ для Томской области ТТУ для Тюменской области , Ямало-Ненецкий и Ханты-МансийскийТУ для Хабаровского края, Еврейской автономной и Магаданской областейТУ для Челябинской и Курганской областейТУ для Чувашской Республики и Ульяновской областиЮжное межрегиональное управление
Составляющие трейса
Трассировка представляет собой древовидную структуру, которая имеет родительскую трассировку и дочернюю трассировку. Трассировки запросов охватывают несколько сервисов и далее разбиваются на более мелкие фрагменты по операциям/функциям, называемые диапазонами. С помощью трасс можно разделить вызов от одного микросервиса к другому.
Уникальный идентификатор для каждого запроса создается в точке входа и передается в качестве контекста трассировки в заголовках запросов последующим системам. Это позволяет анализировать и визуализировать различную информацию о трассировке из нескольких служб в одном месте.
Спецификации
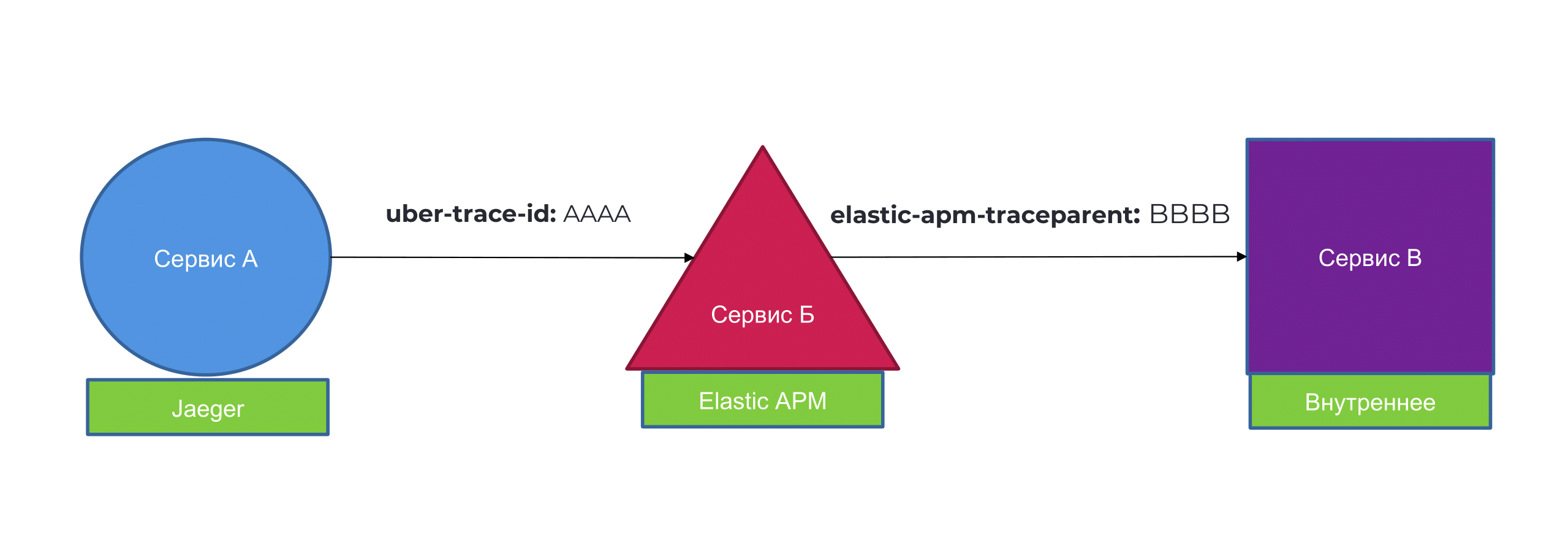
Представьте себе два сервиса: сервис A, использующий Jaeger, сервис B, использующий APM, и сервис C, использующий Haser для хранения трасс. В Jaeger формат заголовка – Uber-trace-id, в Elastic APM – elastic-apm-traceparent.
Поскольку наш запрос проходит между системами разных провайдеров, нам может понадобиться разобрать или сделать что-то еще для работы, но мы не хотим терять информацию. На данный момент формат трассировки несовместим. Здесь все не так плохо.
Открытый комитет по телеметрии и Jaeger, создатели Trace Context, уже работают над стандартом для Trace Context. Вам просто нужно отследить стандарт; они его напишут. Это так же, как HTML.
Вот как будут выглядеть трассы между всеми системами.
Когда к вам придет трасса, у вас больше не будет проблем с ее сохранением, поскольку у нас одинаковые заголовки. Маловероятно, что вы увидите много разных трасс, много разных форматов и т.д. Спецификации, интерфейсы, единообразие – все это замечательно.
И Это уже есть в OpenTelemetry, и оно прекрасно работает. NET впереди всего остального мира.
S P был анонсирован в июне 2021 года Дэвидом Фаулером. Разбор контекста W3C автоматически поддерживается в NET Core 3.0.
Когда приходит запрос, содержащий заголовок в формате W3C, ASP.NET анализирует его для вас и добавляет заголовок в том же формате при отправке запроса.
Создатели ASP. Мы уже подумали об этом.
Трассировка
Вы можете контролировать приложения, отслеживая их во время выполнения. С помощью трасс можно получить следующую информацию:
- Путь запроса через распределенную систему.
- Время запроса для каждой передачи/восстановления (например, из одной службы в другую).
Ниже приведен пример трассировки запроса, взаимодействующего с двумя микросервисами (сервис рекламного аукциона и сервис интегратора рекламы).
Для захвата и визуализации данных в приведенном выше примере использовался инструмент DataDog. Далее я рассмотрю несколько других методов захвата трасс.
Фитосанитарная въездная декларация ched-pp для стран евросоюза

Согласно решению Европейского парламента и Совета от 14 декабря 2021 года, растения и растительная продукция, подлежащие фитосанитарному контролю, перед въездом в Европейский союз должны представить въездную декларацию, CHED-PP. Этот документ действителен для всех стран-членов Европейского союза и требуется как для транзитных, так и для импортируемых товаров. Чтобы заполнить документ CHED-PP, необходимо зарегистрироваться в электронной системе TRACES-NT и получить подтверждение государственной службы. Декларация CHED-PP должна быть заполнена до начала пограничного контроля. В случае авиаперевозок и в других случаях требуется дополнительное уведомление о прибытии. Груз, ввезенный через систему Traces, можно отследить следующим образом:
- Uusi-новая, обозначается синим цветом;
- Validoitu-одобрен, обозначается зеленым цветом;
- Hylätty-отклонен, обозначается красным цветом.
Доказательства отсутствия болезней в растениях и растительной продукции, импортируемой в Европейский Союз.
Заключение
Наличие журналов и трасс само по себе, безусловно, полезно. Однако, когда они коррелируются, они могут стать очень мощным инструментом для устранения неполадок в производственной среде, одновременно давая разработчикам представление о здоровье, производительности и поведении распределенных систем. Как вы видели выше, существует несколько способов реализации этого решения. Выбор за вами 🙂